与HEVC类似,VVC采用基于上下文的自适应二进制算术编码(CABAC)对所有底层语法元素进行熵编码。非二进制语法元素映射到二进制码字。符号和码字之间的双射映射(通常使用简单的结构化码字)称为二值化。使用二进制算术编码对二进制语法元素和非二进制数据的码字的二进制符号(也称为bin)进行编码。
CABAC支持两种操作模式:规则模式(使用自适应概率模型对bin进行编码)和不太复杂的旁路模式(使用1/2的固定概率)。自适应概率模型也称为上下文,将概率模型分配给单个bin称为上下文建模。注意,所使用的二值化和上下文建模对编码效率都有显著影响。
所需的编码器和解码器的复杂性主要随着上下文编码的bin(即在常规模式下编码的bin)的数量而增加。但是,它们还受到其他方面的影响,例如连续bin之间的依赖程度、所使用的上下文建模的复杂性,或者算术编码引擎的规则模式和旁路模式之间发生切换的频率。
变换块量化索引的熵编码通常称为变换系数编码。由于在典型的视频比特率下,变换系数level消耗了总比特率的主要部分,因此在编码效率和实现复杂度之间找到合理的折衷是重要的。VVC中变换系数编码的基本概念类似于HEVC中规定的系数编码:
- coded block flag(CBF)指示变换块是否包括任何非零level
- 对于CBF等于1的块,传输前向扫描顺序中最后一个非零level的x和y坐标;
- 从指示的最后位置开始,以反向扫描顺序传输level,并将其组织为所谓的系数组(CG)。CG的bin在multiple passes中编码,其中所有旁路编码的bins被分组在一起以实现高效实现
由于VVC比HEVC支持更大范围的变换大小,因此对变换系数编码的一些方面进行了推广。与HEVC相反,扫描顺序不依赖于帧内预测模式,因为发现这种依赖于模式的扫描仅提供可忽略的改进,并且将不必要地使设计复杂化。
此外,表示level的bin的上下文建模与块大小无关。但是,在HEVC中发现的上下文依赖限制被放宽,并且利用level之间的局部统计依赖来提高编码效率。为了能够利用某些TCQ属性,level的二值化包括一个奇偶校验单元,CG的所有上下文编码单元在一个过程中编码。VVC使用基于变换块的上下文编码单元数量限制,以保持与HEVC类似的worst-case复杂度。
A. Coded Block Flag
编码块标志(CBF)以编码引擎的常规模式进行编码。总共使用了9个上下文(4个用于luma,2个用于Cb,3个用于Cr)。每个上下文为BDPCM模式编码的块保留一个上下文。对于luma,两个上下文仅用于在帧内子分区模式中编码的变换块(参见[32]);这里,所选择的上下文取决于同一编码单元内的前一luma变换块的CBF。为了利用色度分量的CBF之间的统计相关性,根据同位Cb块的CBF来选择未在BDPCM模式中编码的Cr块的上下文。
B. Coefficient Groups and Scan Order
W×H变换块的变换系数level{q}分布在W×H矩阵中。为了实现跨越所有块大小的协调处理,而且为了提高变换块的编码效率,其中信号能量被集中到对应于低水平或低垂直频率的变换系数中,变换块被划分为系数组(CG)。使用多个扫描过程以统一的方式对每个CG的level进行编码。由于VVC还支持宽度和高度小于4的块大小,因此CG的形状取决于变换块大小,如表II所示。对于具有至少16个系数的变换块,CG总是包括16个level;对于较小的块,使用2×2级的CG。CG的编码顺序由图3所示的反向对角线扫描给出。与CG大小无关,CG对角线从变换块的右下角到左上角进行处理,其中每条对角线沿左下方向进行扫描。CGs内部level的编码顺序由相同的反向对角扫描指定。
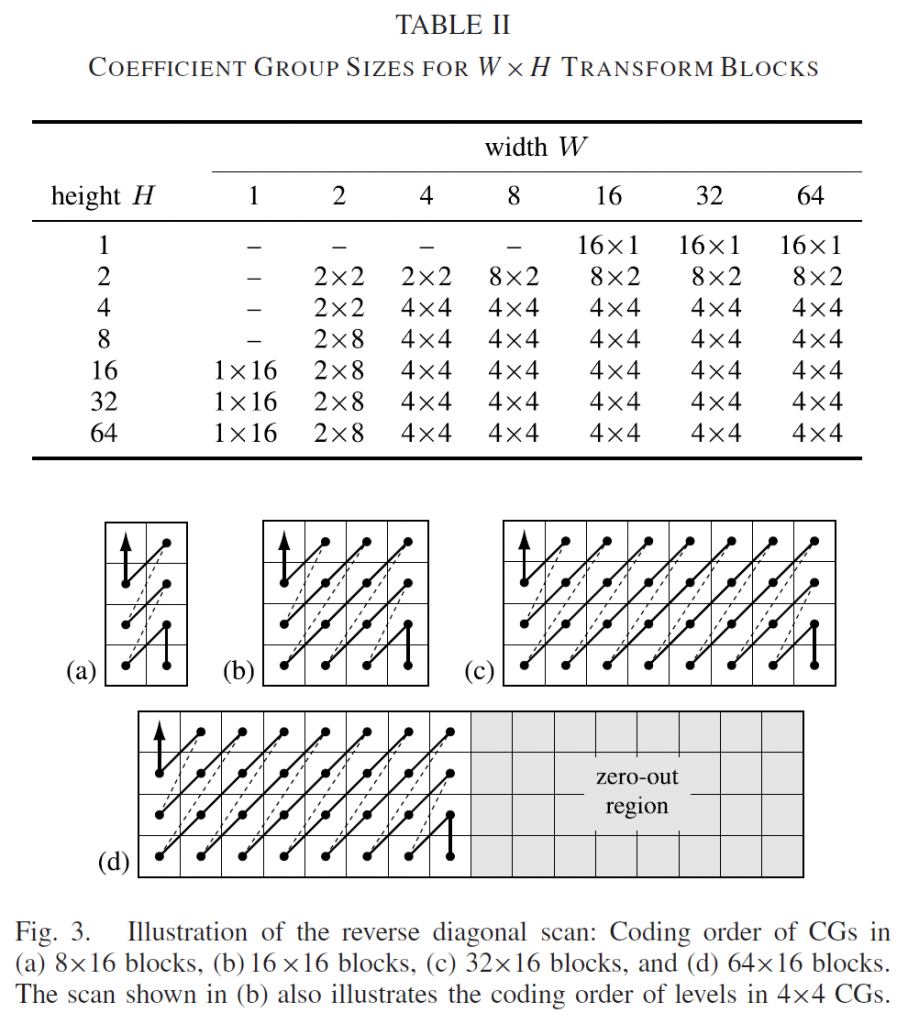
为了限制大变换大小的worst-case解码器复杂性,高频位置的变换系数被迫等于零。非零量化索引只能出现在变换块左上角的min(W,Wn)×min(H,Hn)区域中,其中Wn×Hn表示可以在解码器侧推断的非零输出区域的大小。该区域外的CG未编码,因此被排除在扫描之外,如图3d。在大多数情况下,Wn×Hn等于32×32,这是非零输出区域的最大支持大小。尽管VVC为DCT-II以外的变换指定了较小的非零输出区域,但这通常不会影响变换系数编码,因为指定所用变换的语法元素是在level之后编码的,并且它们取决于某些区域中非零level的存在。唯一的例外是亮度块,最大值为(W,H)≤32,以特殊子块变换模式编码。
如果启用了非DCT-II变换(在序列级别上),则始终使用非DCT-II变换对这些块进行编码,因此,推断出non-zero-out区域的大小等于16×16
C. Last Significant Coefficient Position
与在HEVC中类似,通过以前向扫描顺序(即编码顺序中的第一个非零level)发送最后一个非零level的位置来消除与高频分量相关的系数的零量化索引的显式编码。这不仅提高了编码效率,而且减少了上下文编码的bin的数量。
分别对应于系数level矩阵中的列号和行号的x和y坐标彼此独立地传输。如表III所示,每个component由前缀码字和(可能为空的)后缀码字的组合表示。前缀部分指定值的间隔。使用截断一元(TU)二值化对其进行二值化,并以常规模式对bin进行编码。表示变换块的non-zero-out区域的最后一个间隔的前缀部分被截断。也就是说,如果x坐标的min(W,Wn)或y坐标的min(H,Hn)等于表中最后一列中的数字,则不对表III中括号内的零位进行编码。特别是,如果相应的块宽度或高度等于1,则完全跳过坐标的编码。后缀部分表示前缀部分指示的间隔内的偏移量。它是二值化使用固定长度(FL)二值化和编码在旁路模式。只有值大于3的x和y坐标具有后缀部分。
在解码器侧,导出最后有效level的x和y坐标的值如下。设\(v_{pre}\)是前缀码字中等于1的bin数。然后,要解码的后缀bin的数量\(n_{suf}\)由以下公式导出
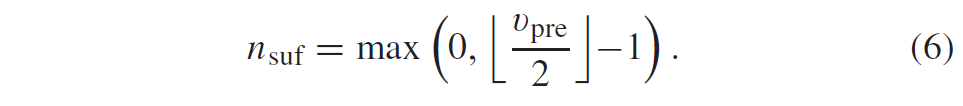
\(v_{suf}\)是后缀码字(二进制表示)指定的值,解码后的坐标值last根据
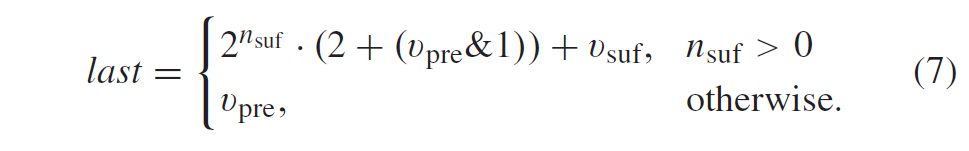
先signal x坐标的前缀部分,然后signal y坐标的前缀部分。对于分组旁路编码bins,后缀部分在前缀码字之后进行编码。x和y坐标的前缀bins使用单独的上下文模型集进行编码。表IV列出了表示集合内使用的概率模型的上下文偏移量。选择的模型取决于是否对亮度块或色度块进行编码、变换块的宽度或高度以及前缀码字内的bin编号。请注意,对于存在zero-out的大型变换块,变换维度(而不是非零输出区域的维度)用于导出上下文偏移。总共有46个上下文(40个用于亮度,6个用于色度)用于编码最后的系数位置。
D. Binarization and Coding Order
从包含最后一个非零level(如x和y坐标所示)的CG开始,CG以编码顺序传输(通过反向对角线扫描给出)。为CG编码的第一个语法元素是sb_coded_flag。如果此标志等于0,则表示CG仅包含零个级别。对于第一个CG(包含最后一个非零level)和最后一个CG(包含DClevel),不编码sb_coded_flag,但推断为等于1。sb_coded_flag以常规模式编码。
选择的上下文取决于右边的CG或下面的CG是否包含任何非零级别,其中为亮度和色度指定了单独的上下文集。总共使用了4个上下文(2个用于亮度,2个用于色度)。对于sb_coded_flag等于1的CGs,按照以下说明对电平值进行编码。
选择系数level的二值化和编码顺序来支持TCQ和常规量化的有效熵编码。由于TCQ中使用的两个标量量化器Q0和Q1的结构不同,电平等于0的概率在很大程度上取决于所使用的量化器。为了在上下文建模中利用此效应,同时分组上下文编码和旁路编码的bin,二值化包括专用奇偶校验标志,用于在熵编码期间确定TCQ状态。
通过另外考虑实现良好编码效率所需的上下文编码bins的数量以及连续bins之间的相关性,选择了表V中所示的二值化。量化索引的绝对值|q|被映射到bin sig(大于0)、gt1(大于1)、par(奇偶性)、gt3(大于3)和非二进制余数rem。
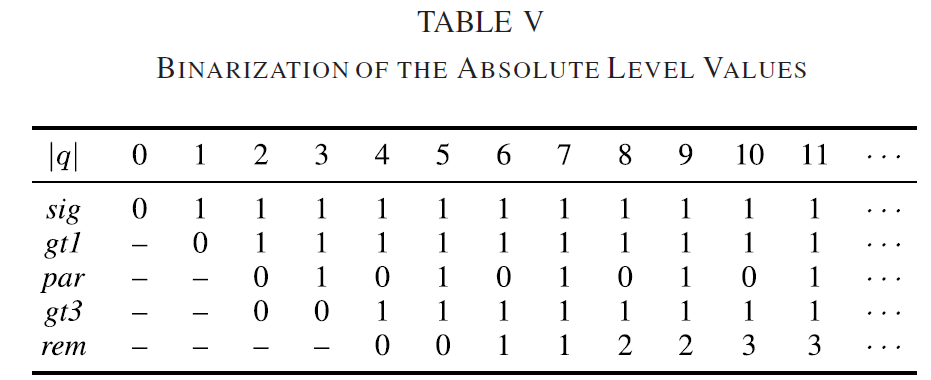
CG的语法元素在扫描位置上进行多次编码。与HEVC不同,在HEVC中,每个系数的单个语法元素在每个扫描过程中进行编码,VVC在单个过程中对每个系数最多编码4个语法元素。
在pass 1中,上下文编码的存储单元sig、gt1、par和gt3以交错方式进行编码(即,在继续下一个扫描位置之前对一个扫描位置的所有存储单元进行编码)。注意,驱动TCQ状态机的奇偶校验bin包括在第一个过程中,以便为TCQ情况启用sig bin的有效编码。对于可以推断sig bin等于1的扫描位置(例如,对于最后一个有效位置),不发送信号。gt1、par和gt3 bin的存在按照表V中的规定进行控制。非二进制余数rem在pass 2中进行编码。使用与HEVC中类似的参数码对其进行二值化,并在旁路模式下对产生的bin进行编码。
为了增加worst-case下的吞吐量,可在第一次过程中编码的上下文编码bin的数量受到限制。为了允许上下文编码的bin在cg之间的适当分布,在变换块的基础上指定限制。N是变换块非零输出区域中变换系数的数量,上下文编码bin的最大允许数量设置为1.75 N。如果bin预算在CG之间平均分配,则这将对应于每个CG 28个bin,这仅略高于HEVC中规定的限制(25个bin)。
对上下文编码的bins的限制如下所示。如果在扫描位置的开始处,用于变换块的已编码sig、gt1、par和gt3 bin的总数超过1.75 ×N – 4,即预算中剩余的bin不到4个,则终止第一个编码过程。在这种情况下,剩余扫描位置的绝对值|q|在pass 3中被编码,它们由语法元素decAbsLevel表示,这些元素在旁路模式下被完全编码。
最后,在pass 4中,CG的所有非零level的符号以旁路模式进行编码。如果启用SDH且CG内最后一个和第一个非零level的扫描索引之间的差值大于3,则不发送最后一个非零level的符号。图4示出了将level数据组织到不同扫描过程中。

E. Context Modeling
为了有效地利用条件统计进行算术编码,VVC使用了一组相当大的上下文模型对bin的sig、gt1、par和gt3进行编码。除了TCQ状态,上下文建模还利用了空间相邻量化索引之间的统计相关性。
sig的上下文取决于相关的TCQ state \(s_k\)、变换块内系数的对角位置d=x+y,以及图5a所示的局部模板T内部分重建的level的绝对q*的总和。部分重建的绝对level由相邻扫描位置的已编码的bin给出,并且可以根据
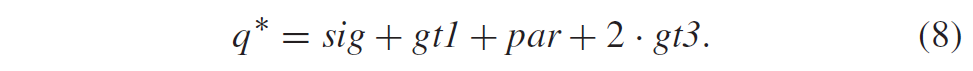
对于亮度块,指示所使用的自适应概率模型的上下文索引\(c_{lum}^{sig}\)根据
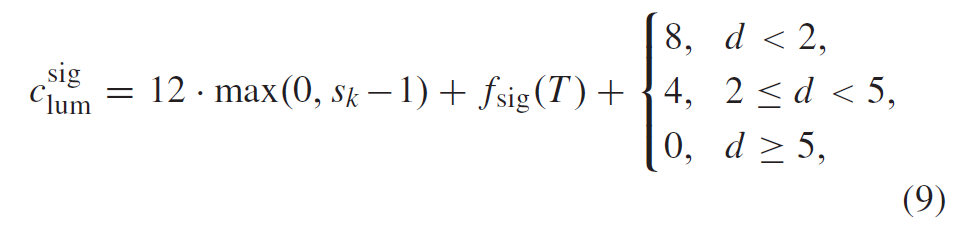
和
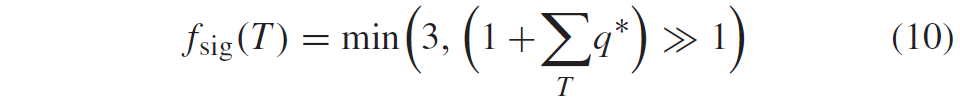
作为局部模板T内部分重建level q*的函数。对于色度块,仅使用两类对角位置(d<2和d≥2)。上下文索引\(c_{lum}^{chr}\)由
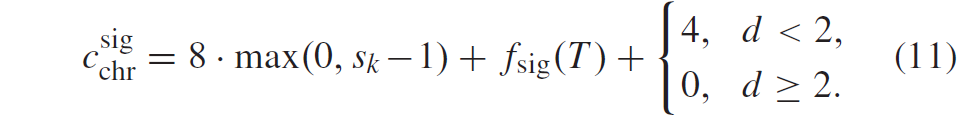
当TCQ未启用时,TCQ state \(s_k\)的值设置为0。总共使用60个上下文模型对sig bin进行编码(36表示luma,24表示色度)。
为gt1、par和gt3选择的概率模型不依赖于TCQ状态,因为发现它只提供很小的好处。计算单个共享上下文偏移量以选择这些语法元素的概率模型。根据系数的对角线位置d(4类luma,2类色度)和max(0,q*-1)之和在本地模板T内选择,使用
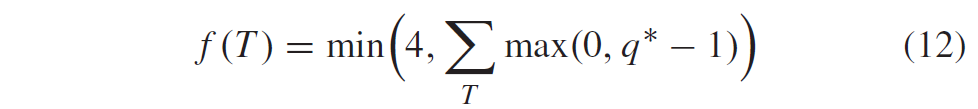
作为局部模板T内部分重建level q*的另一个函数,亮度块和色度块的上下文索引\(c_{lum}\)和\(c_{chr}\)分别由下式给出
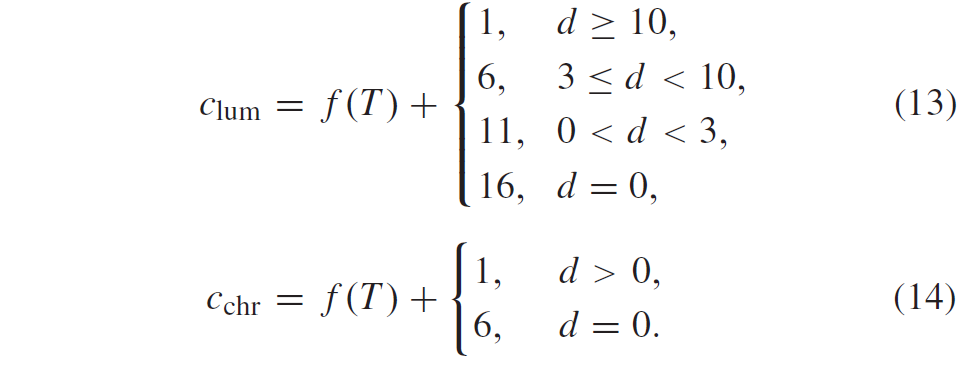
此外,对于最后一个系数位置,使用单独的上下文(由\(c_{lum}=0\)和\(c_{chr}=0\)给出)。对于每个gt1、par和gt3 bins,使用32个概率模型(21个用于亮度,11个用于色度)。
F. Binarization of Bypass-Coded Level Data
第二遍中编码的语法元素rem表示绝对level的余数。如果相关的gt3 bin等于1,则仅针对扫描位置发送它们。q*是根据(8)部分重建的level,level的绝对值|q|由下式给出
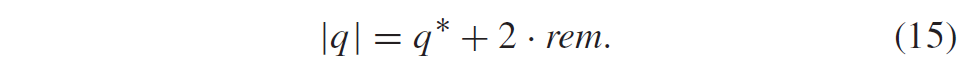
与HEVC中的余数值类似,使用截短的Rice(TR)和Exp-Golomb(EG)码的组合对表示在第三遍中编码的绝对级别的余数rem和语法元素decAbsLevel进行二进制化。在编码引擎的旁路模式中对生成的bin进行编码。与HEVC不同,TR码的Rice参数是基于本地模板T中的绝对level值|q|的和导出的。使用的本地模板T与第一次编码过程中用于上下文索引导出的模板相同。Rice参数m由
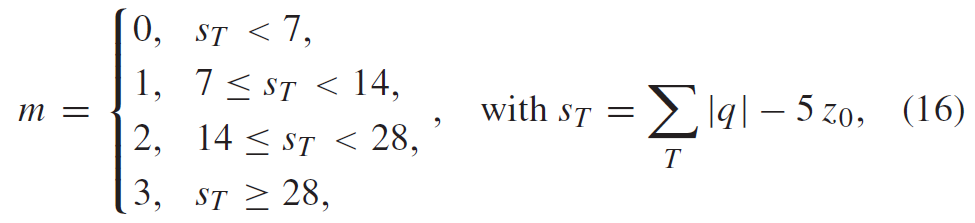
其中,\(z_0\)设置为等于4,用于对余数rem进行编码,\(z_0\)设置为等于0,用于对decAbsLevel进行编码。产生这种差异的原因是decAbsLevel的值指定了完整的绝对级别,而余数rem表示差异rem =(|q| – q∗)/2,具有较小的值。
对于每个Rice参数m,小于\(v_{max}=2^m·6\)的值仅使用m(TRm)阶的TR码进行编码;这对应于长度为6的一元前缀的码。对于大于或等于\(v_{max}\)的值,TRm码与顺序为m+1(EGm+1)的Exp-Golomb码相关联。表VI显示了Rice参数m=0和m=3的二值化,以及TRm和EGm+1码的级联。表中粗体的bin对应于二值化的TRm部分。当组合的码长度将超过32个存储单元时,二值化将略微修改。在这种情况下,Exp-Golomb前缀的长度限制为11个bin(参见表VI中带下划线的m=0条目),32位预算的其余15个bin用于表示后缀部分。

为了提高完全旁路编码电平的编码效率,decAbsLevel的值不直接表示绝对电平值|q|,而是导出为
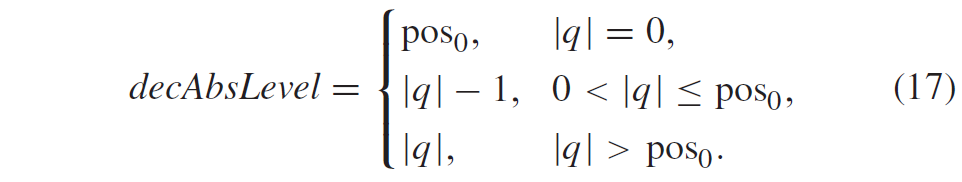
第一个编码过程。Rice参数m由这些值给出,使用与余数rem相同的二值化进行编码。注意,参数\(pos_0\)基本上指定了重新排序的码字表中|q| = 0的码字位置。根据Rice参数m和TCQ状态\(s_k\),根据
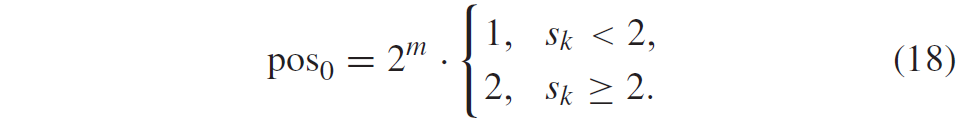
G. Transform Skip Residual Coding
除了上述用于变换系数的规则残差编码(RRC)之外,VVC还包括用于Transform Skip模式中的量化索引的专用熵编码,其被称为Transform Skip残差编码(TSRC)。它主要是为了提高屏幕内容的编码效率而设计的,可以在slice级别启用。启用时,TSRC方案用于对TS块的量化索引进行编码;未启用时,使用规则残差编码对TS块的量化索引进行编码。
与常规残差编码相比,最后一个非零电平的位置不被传输,并且按照前向扫描顺序编码,即从左上角系数开始,然后到右下角系数。与RRC类似,CG的语法元素在扫描位置的多个过程中进行编码,并且对上下文编码的bins的数量应用相同的限制。只要未达到此限制,就使用三个过程对level进行编码,如图6所示。
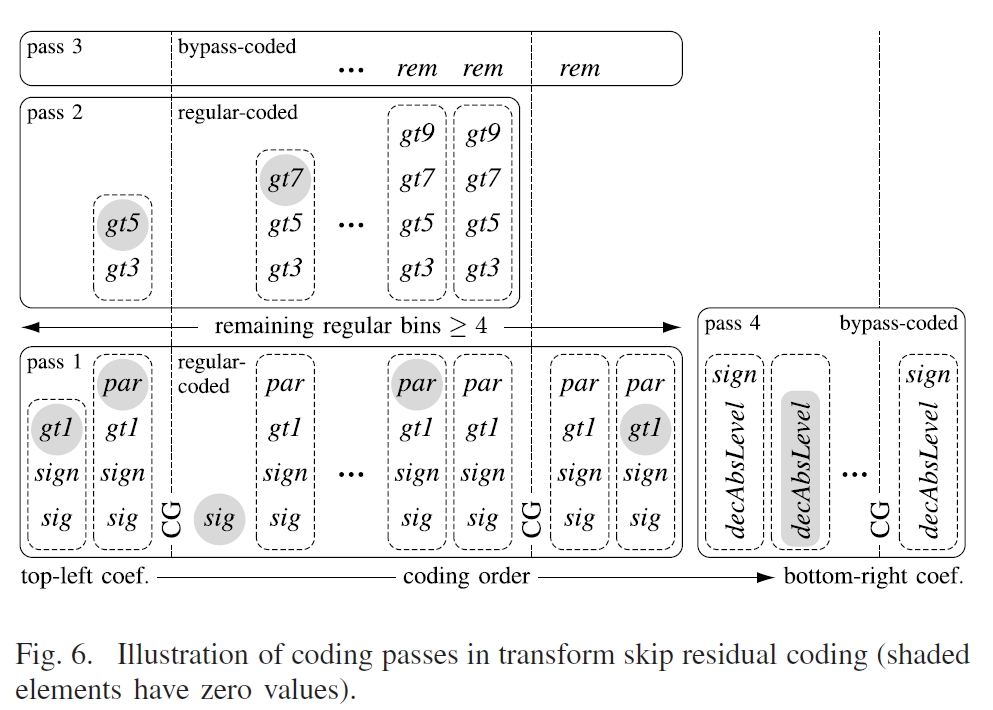
在第一个过程中,使用自适应概率模型对sig、sign、gt1和par的bin进行交织和上下文编码。如图5b所示,局部模板也应用于TSRC中,用于导出上下文索引,但它仅包括两个相邻的系数位置。因为,在TS块中,连续符号通常具有相似性的值,符号标志包含在第一次传递中,并在编码引擎的常规模式下进行编码。如果在pass 1后仍未达到常规编码bin的限制,则在pass 2时,每个系数最多有四个大于x的标志(gt3、gt5、gt7和gt9)被编码。这些bins也是上下文编码的。最后,在pass 3中,绝对level(rem)的余数以旁路模式编码。注意,根据第二次扫描期间扫描位置是否达到bins限制(因此,无法对gt3 bin进行编码),余数可以具有不同的含义。对于第一次扫描中未传输数据的所有扫描位置,在pass 4中以旁路模式对完全绝对值(decAbsLevel)以及相关符号标志进行编码。rem和decAbsLevel的Rice参数m始终设置为1。
《变换系数编码》有一个想法