对于所有现代基于块的混合视频编码,变换是去除预测残差块中空间冗余的重要部分。此外,现有的方向性帧内预测导致预测残差中的方向性模式,并且导致变换系数的可预测模式。变换系数中的可预测模式主要在低频分量中观察到。因此,在本文中,引⼊了⼀种称为低频不可分离变换(LFNST)的不可分离变换,以进⼀步压缩低频主变换系数之间的冗余,低频主变换系数是传统方向帧内预测的变换系数.

提议的 LFNST 是直接矩阵乘法,因此它不需要多次迭代,而多次迭代会导致变换处理中出现不希望的延迟。提议的 LFNST 包含在称为通⽤视频编码 (VVC)的下⼀代视频编码标准中。
I. INTRODUCTION
在 HEVC 的第一个版本完成后,已经研究了具有超越高效视频编码标准 (HEVC) 能力的高级视频压缩技术。有关未来视频编码的活动是在ITU-T 视频编码专家组 (VCEG) 和ISO/IEC 运动图像专家组 (MPEG)的联合视频探索小组 (JVET) 内进行的,该专家组开发了联合探索模型(JEM) ),它现在正积极致力于开发称为通用视频编码 (VVC) 的下⼀个视频编码标准。 VVC 的主要⽬标是指定⼀种视频编码技术,其压缩能力大大超过此类标准的前几代,并且还支持在更广泛的应用中使用视频编解码器,包括超高-清晰度视频(例如,具有 3840×2160 或7620×4320 图像分辨率和 10 或 12 位的位深度,如 ITU-R BT.2100建议书所规定),具有高动态范围和宽色域的视频,以及用于身临其境的媒体应⽤,例如 360° 全向视频,以及先前视频编码标准 JVET-O2001[1] 通常解决的应⽤。 VVC中加⼊了许多先进的压缩技术,它包含了更多高级变换技术,例如多变换集 (MTS) 和低频不可分离变换 (LFNST)。本文重点介绍 LFNST 视频编码技术。
变换一直是去除预测残差块中空间冗余的重要编码工具。预测残差的空间冗余特性取决于预测模式。特别是,在帧内编码模式中,当使用仍在VVC 中使用的方向性帧内预测时,已经观察到方向性预测残差模式。方向预测残差产生变换系数,其中⼀些低频分量可能是可预测的模式,具体取决于帧内预测方向。因此,引⼊称为低频不可分离变换(LFNST)的不可分离变换以进⼀步压缩低频主变换系数之间的冗余,低频主变换系数是来自传统定向帧内预测的变换系数。提议的 LFNST 是直接矩阵乘法,因此它不需要多次迭代,而多次迭代会导致不希望的延迟并阻止变换处理中的并行执行。
II. BACKGROUND
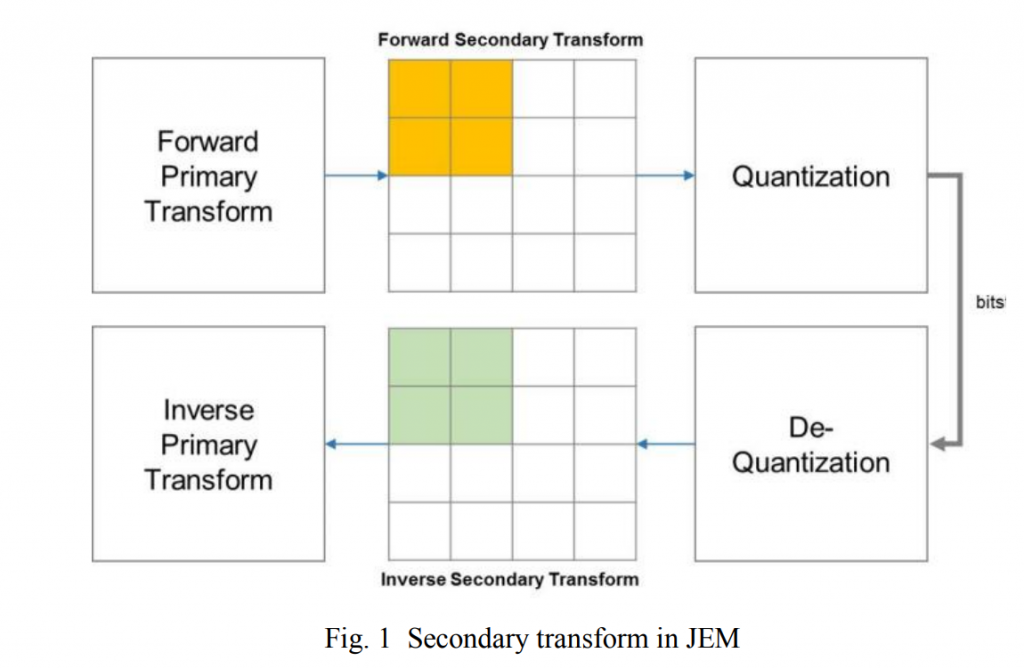
在 JEM 中,二次变换应用于前向初级变换和量化(在编码器)之间以及去量化和反向初级变换(在解码器端)之间。 如图 1 所示,执行 4×4(或 8×8)二次变换取决于块大小。 例如,4×4 二次变换适用于小块(即 min (width, height) < 8),8×8 二次变换适用于每个 8×8 块的较大块(即 min (width, height) > 4)。
下面以输入为例描述不可分离变换的应用。 为了应用不可分离变换,4×4 输入块 \(X\)
\(\vec{X} =\begin{Bmatrix}
X_{00} & X_{01} & X_{02} & X_{03}\\
X_{10} & X_{11} & X_{12} & X_{13}\\
X_{20} & X_{21} & X_{22} & X_{23}\\
X_{30} & X_{31} & X_{32} & X_{33}
\end{Bmatrix}\)
首先表示为一维向量\(\vec{X}\)。
不可分离变换计算为\(\vec{F} =T\cdot \vec{X}\),其中\(\vec{F}\)表示变换系数向量,\(T\)是一个 16×16 的变换矩阵。随后使用该块的扫描顺序(水平、垂直或对角线)将 16×1 系数向量\(\vec{F}\)重组为 4×4 块。具有较小索引的系数将与较小的扫描索引一起放置在 4×4 系数块中。总共有 35 个变换集,每个变换集使用 3 个不可分离的变换矩阵(内核)。从帧内预测模式到变换集的映射是预先定义的。对于每个变换集,选择的不可分离次级变换候选者进一步由显式发送的次级变换索引指定。在变换系数之后,每个 Intra CU 在比特流中用信号通知索引一次。为了降低二次变换的复杂度,JVET-B0059 [2] 在二次变换的计算中提出了一种新的超立方给定变换(HyGT)。这种正交变换的基本元素是吉文斯旋转,它由旋转正交矩阵定义。图 2 描绘了二级变换结构。
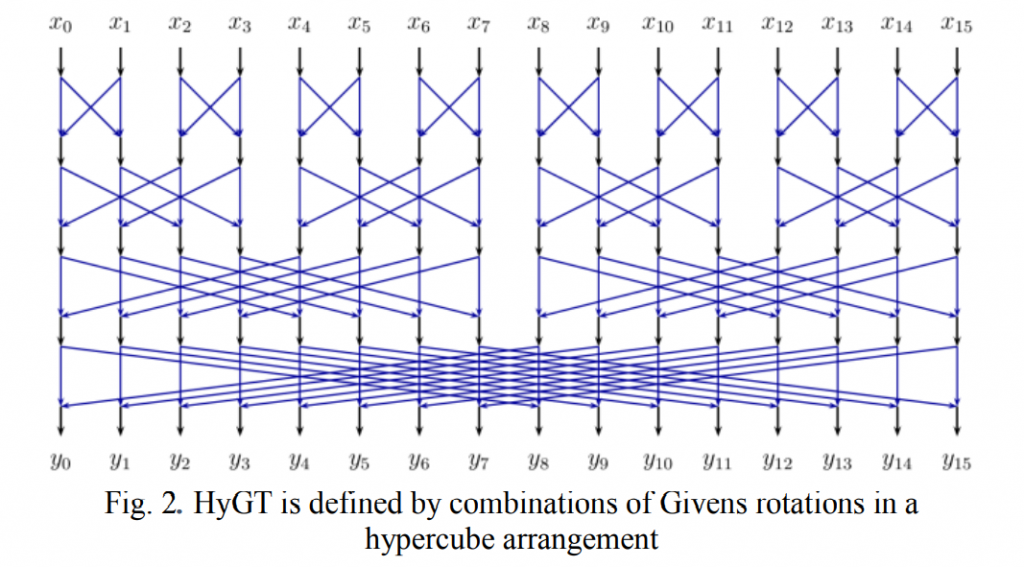
HyGT 的乘法复杂度很高。 变换的分层结构也给硬件设计带来了问题,因为相邻阶段之间的数据依赖性限制了并行性。
III. ALGORITHM DESCRIPTION OF LFNST
LFNST 最初是在 JVET-K0099 [3](以前称为缩减二次变换或 RST)中引入的。 LFNST 和 HyGT 的原始版本有 35 个变换集,每个变换集有 3 个不可分离的变换矩阵(内核),这需要大量的内存使用,不适合硬件设计。 JVET-L0133 中引入了 4 个变换集(而不是 35 个变换集)映射,最后在 VTM5 中采用的 JVET-N0193 [4] 中引入了每组 2 个内核的 4 个变换集。 在本文中,16×48 和 16×16 矩阵分别用于 8×8 和 4×4 块。 为方便起见,16×48 变换表示为 LFNST8x8,16×16 变换表示为 LFNST4x4。 图 3 表示正向和反向 LFNST。
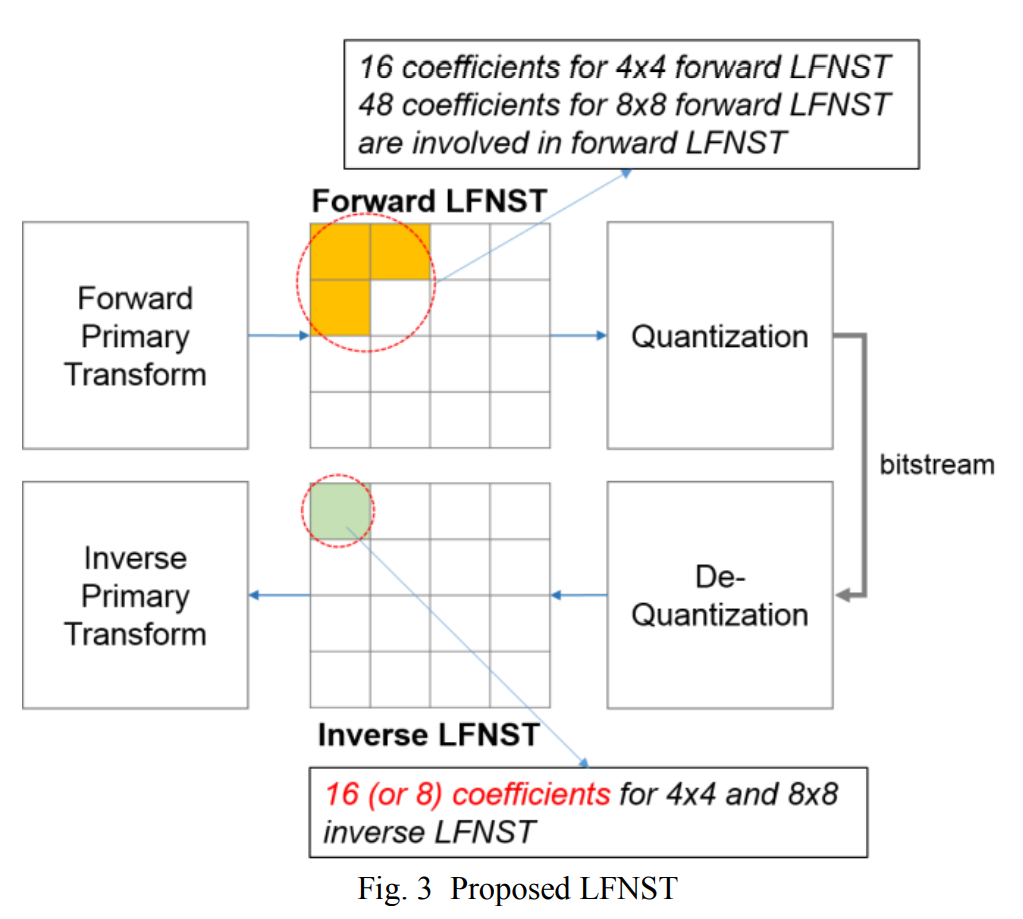
A. LFNST computation
LFNST或缩减变换(RT)的主要思想是将一个N维向量映射到不同空间中的一个R维向量,其中R/N(R < N)是缩减因子。 RT矩阵是一个R×N矩阵,如下:

其中变换的 R 行是 N 维空间的 R 个基。 RT 的逆变换矩阵是其正向变换的转置。 正向和反向 LFNST 如图 4 所示。

在本文中,应用了缩减因子为 3(1/3 大小)的 LFNST8x8。 因此使用 16×48 直接矩阵,每个矩阵从左上角 8×8 块中的三个 4×4 块中获取 48 个输入数据,不包括右下角 4×4 块(图 5)。我们将此区域称为 LFNST8x8 的感兴趣区域或 ROI8x8 .
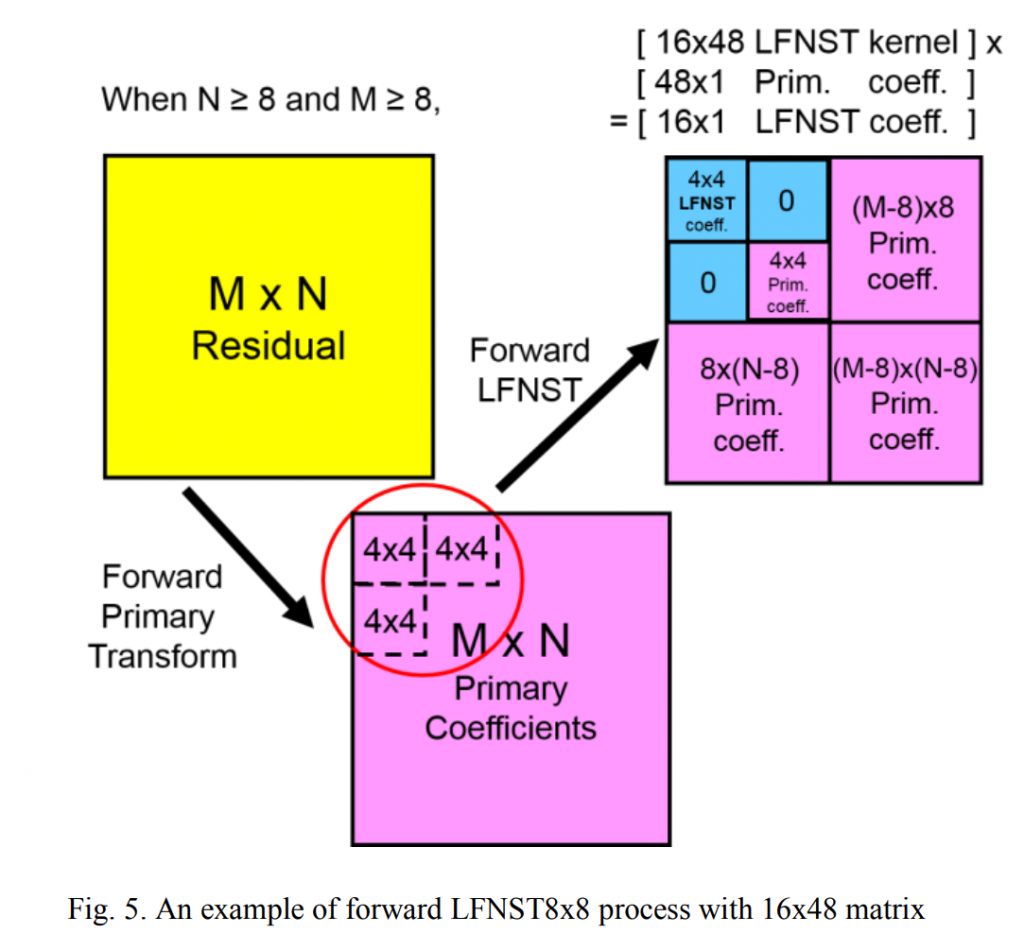
换句话说,在解码器端使用 48×16 逆 LFNST 矩阵来生成 ROI8x8 中的核心(主)变换系数。 前向 LFNST8x8 使用 16×48(或 8×48 用于 8×8 块)矩阵,因此它仅在给定 ROI8x8 内的左上 4×4 区域中产生非零系数。 换句话说,如果应用 LFNST,那么除了左上角 4×4 区域之外的 ROI8x8 将只有零系数。 对于 LFNST4x4,应用 16×16(或 8×16 用于 4×4 块)直接矩阵乘法。
当满足以下两个条件时,有条件地应用逆 LFNST:
- 块大小大于等于给定阈值(W>=4 && H>=4)
- Transform skip 模式标志等于零.
如果变换系数块的宽度 (W) 和高度 (H) 均大于 4,则将 LFNST8x8 应用于变换系数块的 ROI8x8。 否则,LFNST4x4 可以应用于变换系数块的左上 min(8, W) × min(8, H) 区域。
如果 LFNST 索引等于 0,则不应用 LFNST。 否则,应用 LFNST,使用 LFNST 索引选择内核。 LFNST 选择方法和 LFNST 索引的编码将在以下部分中进行说明。
此外,LFNST 应用于帧内和帧间Slice中的帧内 CU,以及亮度和色度。 如果启用dual tree,Luma 和 Chroma 的 LFNST 索引将分别发出信号。 如果dual tree被禁用,单个 LFNST 索引被发送并用于 Luma 和 Chroma。
在第 13 次 JVET 会议上,采用了帧内子分区 (ISP) 作为一种新的帧内预测模式。 选择 ISP 模式时,禁用 LFNST 并且不发出 LFNST 索引信号,因为即使将 LFNST 应用于每个可行的分区块,性能改进也是微不足道的。 此外,对 ISP 预测的残差禁用 LFNST 可以降低编码复杂度。
B. LFNST selection
LFNST 矩阵是从四个变换集中选择的,每个变换集由两个变换组成。 应用哪个变换集由帧内预测模式确定,如下所示:
- 如果指示了三种 CCLM 模式之一,则选择变换集 0。
- 否则,按照表1进行变换集选择:
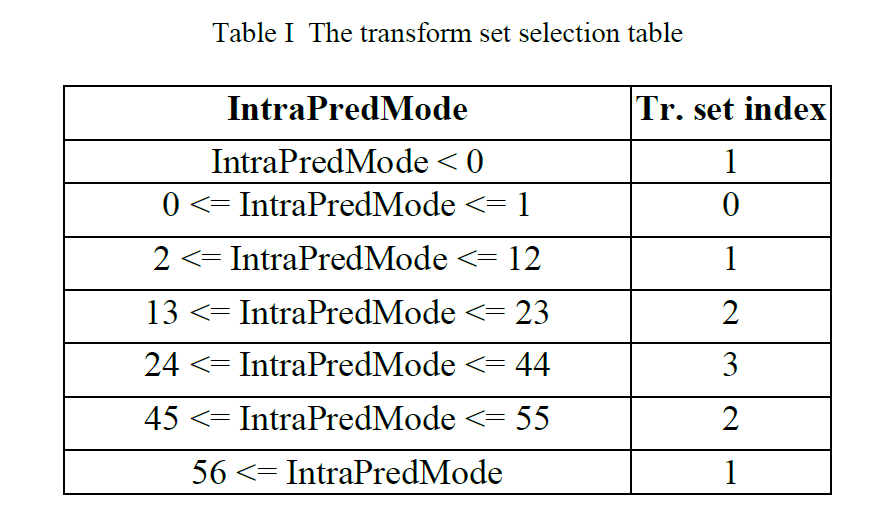
访问表 1 的索引 IntraPredMode 的范围为 [-14, 83],这是用于广角帧内预测的变换模式索引。
C. LFNST Signaling
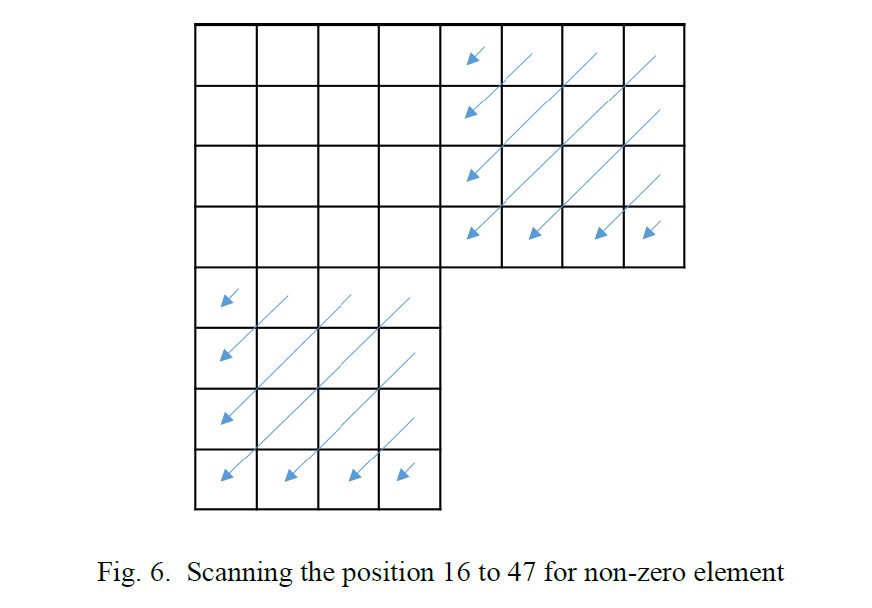
R = 16 的前向 LFNST8x8 使用 16×48 矩阵,因此它仅在给定 ROI8x8 内的左上角 4×4 区域中产生非零系数。 换句话说,如果应用了 LFNST,那么除了左上角的 4×4 区域之外的 ROI8x8 只生成零系数。 因此,当在 ROI8x8 中检测到除了左上 4×4(如图 6 所示)之外的任何非零元素时,LFNST 索引不会被编码,因为这意味着没有应用 LFNST。 在这种情况下,LFNST 索引被推断为零。
D. Worse case multiplication handling of LFNST
根据硬件专家的意见,LFNST 需要将每个样本的最坏情况乘法次数限制为小于或等于 8。
如果我们使用 LFNST8x8 和 LFNST4x4,当所有 TU 都由 4×4 TU 或 8×8 TU 组成时,就会出现乘法计数的worst-case情况。 因此,前 8×48 和 8×16 矩阵(换句话说,每个矩阵中从顶部开始的前 8 个变换基向量)分别应用于 8×8 TU 和 4×4 TU。 在块大于 8×8 TU 的情况下,不会发生worst-case的情况,因此 LFNST8x8(即 16×48 矩阵)应用于左上角的 8×8 区域。 对于 8×4 TU 或 4×8 TU,LFNST4x4(即 16×16 矩阵)仅应用于不包括其他 4×4 区域的左上角 4×4 区域,以避免worst-case的情况发生。 在 4xN 或 Nx4 TU (N ≥ 16) 的情况下,LFNST4x4 分别应用于两个相邻的左上角 4×4 块。 通过上述简化,worst-case下的乘法次数变为每个样本 8 次。
IV. EXPERIMENTAL RESULTS
根据 JVET-M1010 [5] 中定义的通用测试条件和 JVET-M1026 [6] 中的核心实验描述,基于 VTM-4.0 参考软件实现了所提出的方法。 执行所有All Intra (AI) 和随机访问 (RA) 测试。
在 A 部分,报告了inter MTS 关闭的 AI、RA 和 LD 结果,其中与 VTM anchor相比,编码时间为 126% (AI)、111% (RA) 和 108% (LD),BD 速率变化为 -1.34% (AI)、-0.69% (RA) 和 -0.22% (LD)。
在 B 部分中,报告了启用 inter MTS 的 RA 和 LD 结果,其中与 VTM anchor相比,编码时间分别为 109% (RA) 和 105% (LD),BD 速率变化分别为 -0.69% (RA) 和 -0.18% (LD)。
最后,在 C 部分报告了 AI 案例的低 qp 结果,其中与 VTM anchor相比,编码时间为 137%,BD 速率变化为 -0.63%。
REFERENCES
[1] B. Bross, J. Chen, S. Liu, “Versatile Video Coding (Draft 6)”, document JVET-O2001, 15th Meeting: Gothenburg, SE, 3–12 July 2019.
[2] X. Zhao, A. Said, V. Seregin, M. Karczewicz, J. Chen, R. Joshi, “TU-level non-separable secondary transform”, Joint Video Exploration Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11, Doc. JVET-B0059, 3rd Meeting
[3] M. Salehifar, M. Koo, J. Lim, S. Kim, “CE 6.2.6: Reduced Secondary Transform (RST)”, document JVET-K0099, Ljubljana, SI, Jul. 2018.
[4] M. Koo, M. Salehifar, J. Lim, S. Kim, “CE6: Reduced Secondary Transform (RST) (CE6-3.1)”, Joint Video Exploration Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC1/SC 29/WG 11 JVET-N0193, 14th meeting, Geneva, CH, 19–27 March 2019.
[5] F. Bossen, J. Boyce, K. Suehring, X. Li and V. Seregin, “JVET common test conditions and software reference configurations for SDR video”, JVET-M1010, 13th JVET meeting, Marrakech, MA, 9–18 Jan. 2019.
[6] X. Zhao et al., “Description of Core Experiment 6 (CE6): Transforms and transform signalling”, JVET-M1026, 13th JVET meeting, Marrakech, MA, 9–18 Jan. 2019.