翻译自 J. Garrett-Glaser, “A novel macroblock-tree algorithm for high-performance optimization of dependent video coding in h. 264/avc,” Tech. Rep., 2009.
x264 有一个复杂的前(lookahead)模块,旨在估计尚未被主编码器模块分析的帧的编码成本。 它使用这些估计来做出各种决策,例如自适应 B 帧、显式加权预测以及带VBV的码率控制的比特分配。 出于速度原因,它在帧的半分辨率版本上运行并仅计算 SATD 残差,不进行量化或重建。
Lookahead 的核心是 x264_slicetype_frame_cost 函数,该函数会被重复调用以计算给定 p0、p1 和 b 值的帧的成本。 p0 是要分析的帧的列表 0(过去)参考帧。 p1 是要分析的帧的列表 1 参考帧。 b 是要分析的帧。 如果p1等于b,则该帧被推断为P帧。 如果p0等于b,则该帧被推断为I帧。 由于 x264_slicetype_frame_cost 可能会作为使用它的算法的一部分在相同的参数上重复调用,因此每个调用的结果都会被缓存以供将来使用。
x264_slicetype_frame_cost 通过为帧中的每个宏块调用 x264_slicetype_mb_cost 进行操作。 由于帧是半分辨率,因此每个“宏块”是 8×8 像素,而不是 16×16。 x264_slicetype_mb_cost 对每个参考帧执行运动搜索。 该运动搜索通常是具有子像素细化的六边形运动搜索。
对于 B 帧,它还检查一些可能的双向模式:类似于 H.264/AVC 的“temporal direct”的模式、零运动矢量以及使用 list0 和 list1 运动搜索产生的运动矢量的模式。 x264_slicetype_mb_cost 还计算近似的intra cost。 所有这些cost都被存储以供将来使用。 这对于宏块树来说很重要,它需要这些信息来进行计算。
The Macroblock-tree algorithm
为了执行上述的信息传播估计,宏块树跟踪每个前瞻帧中每个宏块的传播成本:以 SATD 残差为单位的数值估计,表示未来残差在多大程度上取决于该宏块。 对于前瞻中的所有帧,该值都初始化为零。
宏块树在前瞻中的最后一个minigop 中开始操作,首先对 B 帧进行操作,然后对 P 帧进行操作。 然后,它向后移动到前瞻中的第一帧(要编码的下一帧)。 通过这种方式,宏块树向后工作:它及时向后“传播”依赖关系。 因此,当我们“传播”依赖关系时,我们是在与实际依赖关系本身相反的方向上进行操作:将信息从一个帧移动到其参考帧。
对于每一帧,我们对所有宏块运行传播步骤。 宏块树的传播步骤如下:
- 对于当前宏块,我们加载以下变量:
- intra_cost:该宏块的帧内模式的估计 SATD 成本。
- inter_cost:该宏块的帧间模式的估计 SATD 成本。 如果该值大于intra_cost,则应将其设置为intra_cost。
- propagate_in:当前宏块的propagate_cost。 对于运行传播的第一个帧,故意将propagate_cost设置为零,因为尚未收集该帧的信息。
- 我们计算从该宏块传播到其参考帧中的宏块的信息分数,称为propagate_fraction。 这可以通过公式 1 – intra_cost / inter_cost 来近似。 例如,如果宏块的帧间成本是该宏块的帧内成本的 80%,则我们说该宏块中 20% 的信息源自其参考帧。 这显然是一个非常粗略的近似,但是快速且简单。
- 依赖于该宏块的信息总量(total amount)等于(intra_cost+propagate_in)。 这是所有未来依赖性(直到前瞻边缘)和当前宏块的内部成本的总和。 我们将其乘以propagate_fraction,得到应该传播到该宏块的参考帧的近似信息量,propagate_amount。
- 我们在其参考帧中的宏块之间分割propagate_amount,用于预测当前块。 基于每个宏块用于预测当前宏块的像素数量对分割进行加权。 这可以基于当前宏块的运动矢量来计算。 如果块有两个参考帧(如双向预测的情况),则将传入的值平均分配到两者之间,或者如果启用了加权 B 帧预测,则根据双向预测权重。 然后将propagate_amount 的适当分割部分添加到用于预测的每个宏块的propagate_cost 中。 请注意,如果为了简单起见我们忽略插值滤波器的影响,则每帧中最多有 4 个宏块可用于当前宏块的预测。
该过程的结果是当前帧的参考的propagate_cost值已基于当前帧的内容而增加。 通过对前瞻中的所有帧以相反的顺序重复此操作,我们可以估算出前瞻中每个宏块对前瞻中其余帧的质量的贡献。
最后,将完成步骤应用于我们希望获取最终量化器增量的任何帧中的宏块。 这通常是接下来要编码的几帧。 宏块树的完成步骤使用与传播相同的输入进行操作,但输出 H.264 量化器增量:
\(Macroblock QP Delta = -strength * log2((intra\_cost + propagate\_cost) / intra\_cost)\)
其中strength是从实验中得出的任意因子。 测试表明,对于大多数视频来说,2 是接近最佳的值。 由于 H.264 量化器比例每 6 Qps 精度加倍,这意味着最佳量化器精度似乎与完成步骤中使用的结果值 (1 +propagate_cost/intra_cost) 的立方根大致成比例。
应该注意的是,该算法会导致 QP 增量完全为零的未引用帧,因为没有任何内容传播到它们:
\(Macroblock QP Delta = -strength * log2((intra\_cost + 0) / intra\_cost) = -strength * log2(1) = 0\)
这是有意为之的:根据宏块树的逻辑,所有未引用的宏块都具有相等(因此最小)的值。
Analysis
宏块树在比特分布方面具有许多一致的效果。 其中之一是对 B 帧量化器的影响。 正如简介中提到的,B 帧量化器通常是通过 P 帧量化器的偏移导出的。 宏块树实际上相反:未引用的 B 帧量化器始终相同,而相邻的 P 帧量化器则不同。
其结果实际上是自适应 B 帧量化器偏移。 在高速运动区域,B 帧的量化值往往不会比附近 P 帧的量化值高很多。 在低运动区域,量化器差异要高得多:在某些情况下+4-6 QP 或更多。 值得注意的是,在 x264 中,当宏块树打开时,常规 B 帧量化器偏移将被禁用,因为它们起到相同的作用。
人们可能会类似地假设宏块树可以替代关键帧量化器偏移。 然而,测试表明情况并非如此:宏块树通常会降低整个场景的量化器,而不仅仅是场景中的第一帧。 关键帧量化器偏移对于 PSNR 仍然有用,因此保留在 x264 中。 关键帧量化器偏移的算法推导可能需要某种形式的前瞻量化。
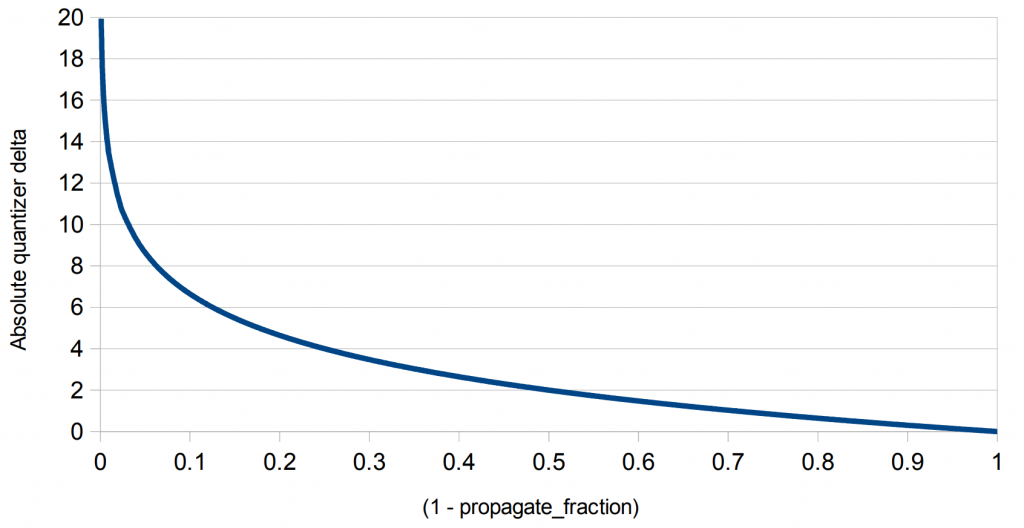
虽然宏块树太复杂而无法实现封闭形式的通用解决方案,但可以从特殊情况输入的解决方案中得出一些见解:全零运动向量、无 B 帧、恒定的intra_cost和恒定的propagate_fraction。 尽管这样的输入完全不切实际,但它提供了对宏块树作为propagate_cost函数进行缩放的方式的深入了解。
令 TREE[N] 为传播 N 帧后的propagate_cost。 令 Y 为常量intra_cost,Z 为常量propagate_fraction,范围为0-1。
\(TREE[0] = 0\)
\(TREE[N] = (TREE[N-1] + Y)*Z\)
对于较大的 N,这可以简单地证明收敛于 Y * (Z/(1-Z))。因此,在这种情况下宏块树的量化器增量按如下比例缩放:
Perceptual considerations
由于宏块树在视频的帧内和帧间之间重新分配比特,因此它特别有可能产生积极和消极的感知后果。 我们在视觉比较过程中注意到这些影响有两个主要类别:运动自适应量化和“pre-echo”。
视频的高运动部分的视觉质量下降是 qcompress 和其他类似算法的感知解释。 因此,与qcompress不同,宏块树不会仅仅因为帧的其他部分在时域上复杂而降低帧的静态部分的质量。 这对于静态背景和重叠图形的情况尤其重要。 从这个意义上说,宏块树是一种注重编码效率的运动自适应量化算法。
“pre-echo”是宏块树设计的自然结果。 宏块的质量取决于它在未来被引用的程度; 如果该宏块很快就会被遮挡(如移动物体的情况)或完全被替换(如场景变化的情况),宏块树将降低其质量。
通常,这种“pre-echo”仅在遮挡/场景变化之前的几帧中可见,并且几乎完全被帧间预测隐藏。 此外,场景变化会导致向后时间掩蔽效应,有助于隐藏此类伪影。 这种向后的时间掩蔽效应持续几十毫秒,足以覆盖一两帧,并且被认为是由人类视觉系统的处理延迟引起的。 这与我们自己对宏块树的非正式视觉测试一致,这也表明此类伪影在视觉上是不可见的。 因此,保存在此类宏块中的比特可以自由地用于视频中的其他地方。
在一种特殊情况下,“pre-echo”是可见的:即强制关键帧。 朴素的宏块树算法将关键帧视为全帧内帧,即使关键帧不是场景变化。 这会导致关键帧之前的几帧质量降低,在关键帧实际上不是场景变化的情况下,这在视觉上可以明显感觉到质量的微小脉冲。
在 x264 中,为了宏块树的目的,通过将强制关键帧视为 P 帧来避免此问题。 请注意,此优化仅在感知优化开启时在 x264 中执行。 忽略这种感知优化可能会对 PSNR 和 SSIM 产生较小的积极影响。