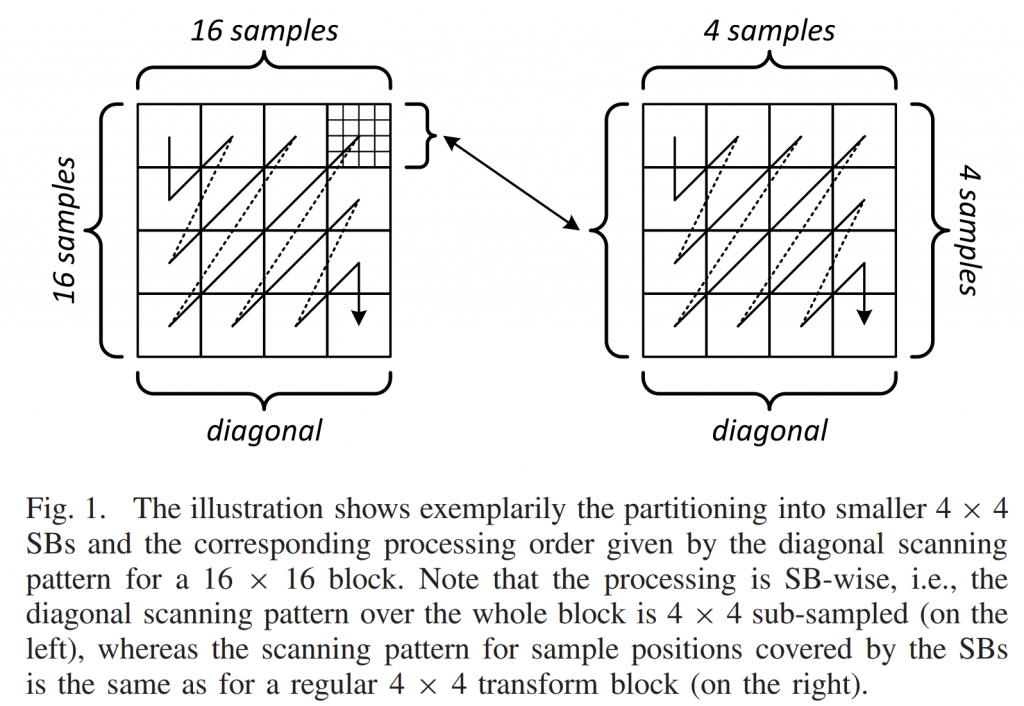
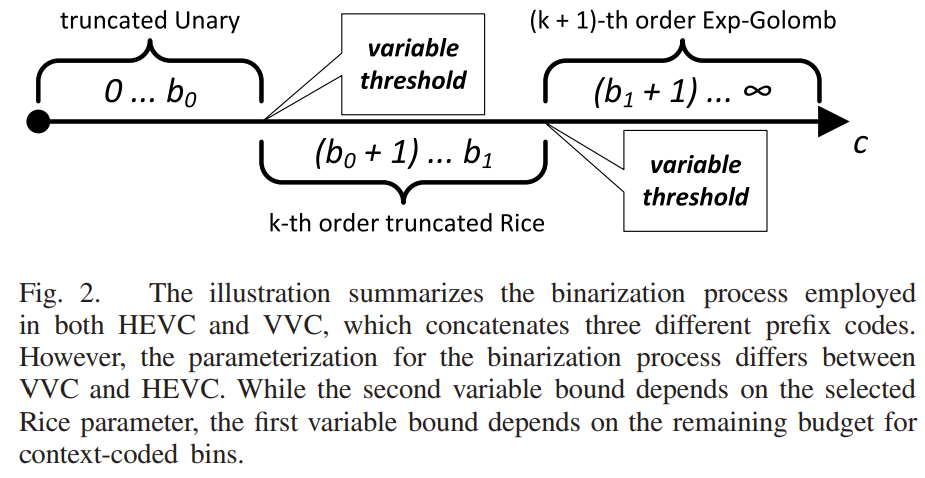
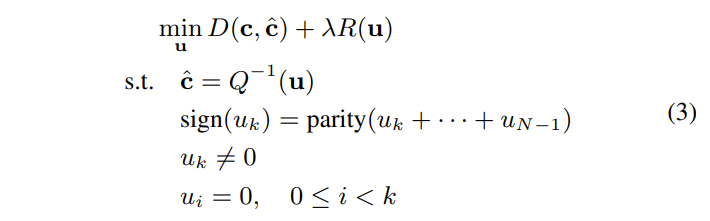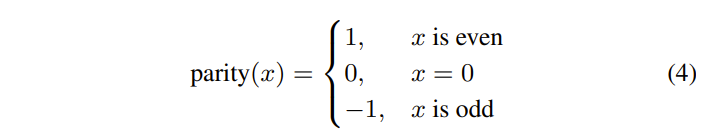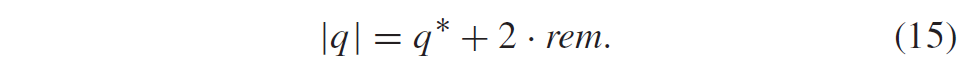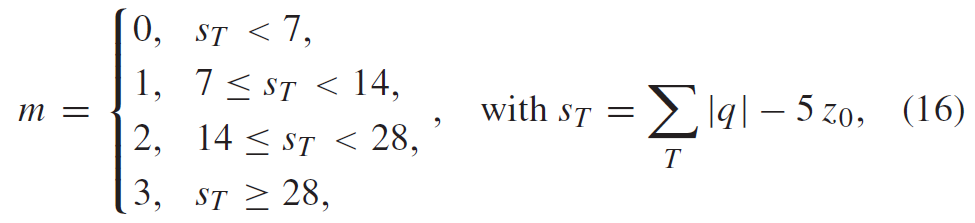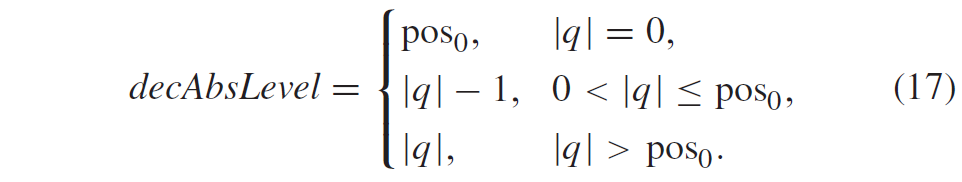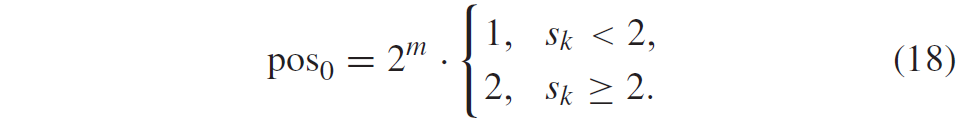Megre模式是HEVC编码标准引入的一项帧间预测编码技术,在VVC编码标准中对Merge模式进行了扩展。包括对候选列表的扩展,增加了HMVP和 Pair-wise average candidates。编码工具新增CIIP (combined inter-intra prediction)、MMVD(merge mode with MV difference)、GEO(geometric partitioning mode)。VVC新提出的affine也存在merge模式,不过affine merge的候选推导和上面几个编码工具是不一样的。本文主要讨论Merge模式候选列表构建。
1 HEVC Merge候选列表构建
HEVC的Merge候选个数最大为5个,构建过程如图1。
图1
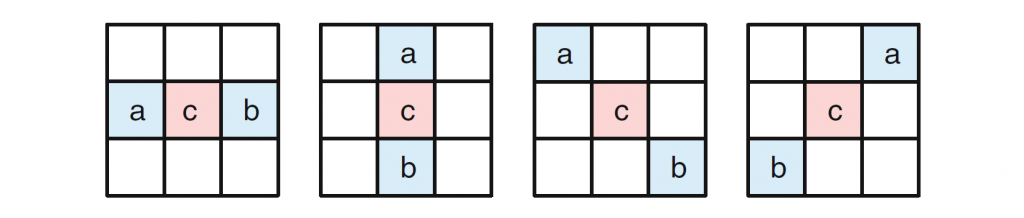
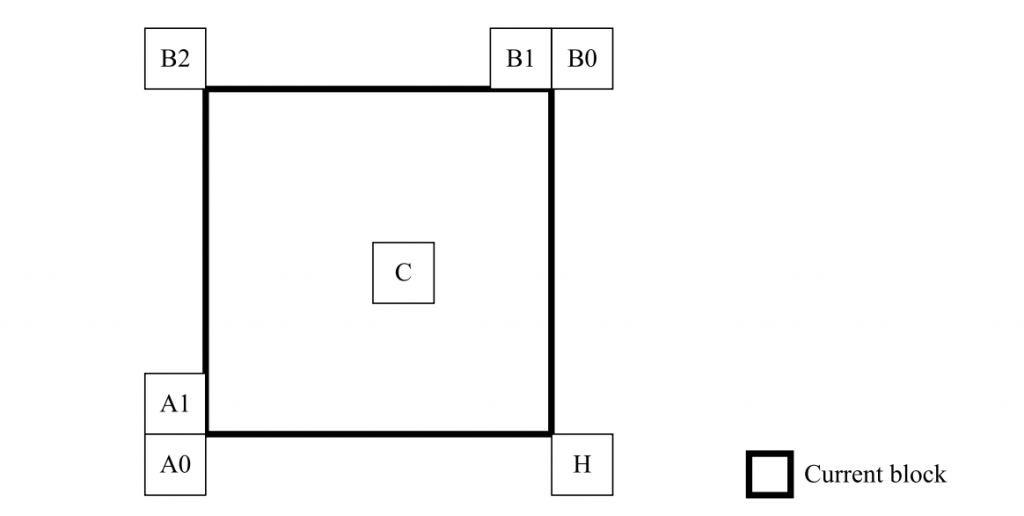
为了构建空域Merge候选,在位于图2所示位置的候选中选择最多四个Merge候选。
图2
构建的顺序是A1→B1→B0→A0→B2。仅当位置 A1、B1、B0 和 A0 的任何 PU 不可用(例如它属于另一个Slice或Tile)或者不是inter mode时才考虑位置 B2。
在A1位置的候选加入后,剩余候选的加入会进行冗余校验,确保将具有相同运动信息的候选排除在列表之外,以提高编码效率。为了降低计算复杂度,仅比较下图3的箭头链接的对,并且仅当候选通过冗余检查时才将其添加到列表中。
图3
在 HEVC 中,一个 CU 可能会被划分为多个 PU,这可能会对Merge模式带来冗余。图4描绘了从 CU 中分别按 N × 2N 和 2N × N 模式划分的“第二个 PU”。
图4
当第二个 PU 从一个 CU 划分 N × 2N 时,位置 A1 的候选者不考虑用于列表构建。事实上,通过选择这个候选者,两个 PU 将共享相同的运动信息,这对于 CU 中只有一个 PU 的情况是多余的。 类似地,当第二个 PU 从一个 CU 被分割为 2N × N 时,不考虑位置 B1。
在时域Merge候选的推导中,TMVP 候选是从存储在位置 H 或 C 的 MV 推导出来的,如图 1 所示的并置图片,类似于 AMVP 模式的 TMVP 候选。 对于Merge候选列表中的 TMVP 候选,MV 将被缩放到相应参考帧列表中具有参考索引 0 的参考帧。
除了时空Merge候选之外,还有两种附加类型的Merge候选:组合的双向预测Merge候选和具有 (0, 0) 运动向量的零运动候选。 组合的双向预测Merge候选是通过仅利用 B Slice的时空Merge候选来生成的。 通过组合具有参考列表0的第一Merge候选和具有参考列表1的第二Merge候选来生成组合双向预测候选,其中第一和第二Merge候选根据预定义顺序从Merge候选列表中的可用Merge候选中选择。这两个MV将形成新的双向预测候选。如果未满足Merge候选列表,则将向列表添加零运动候选以填充列表。
2 VVC Merge候选列表构建
2.1 空域候选推导
VVC中空域Merge候选的推导与HEVC相同,只是前两个Merge候选的位置交换了。在位于图 5 所示位置的候选中,最多选择四个Merge候选。推导顺序为 B1、A1、B0、A0 和 B2。仅当位置 B0、A0、B1、A1 的一个或多个 CU 不可用(例如它属于另一个Slice或Tile)或者不是inter mode时,才考虑位置 B2。在A1位置的候选加入后,剩余候选的加入进行冗余校验,保证将具有相同运动信息的候选排除在列表之外,从而提高编码效率。为了降低计算复杂度,在提到的冗余校验中并未考虑所有可能的候选对,与HEVC一样仅考虑与图 3 中的箭头链接的对,并且仅当用于冗余校验的相应候选具有不同的运动信息时,才将候选添加到列表中。
图5
2.2 时域候选推导(TMVP)
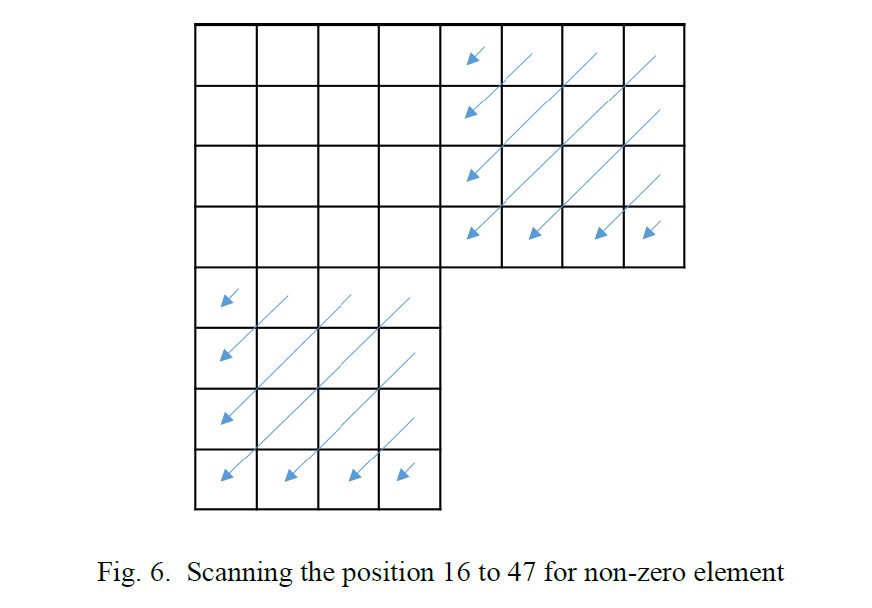
在此步骤中,仅将一个候选者添加到列表中。 特别地,在该时域Merge候选的推导中,基于属于并置参考图片的 co-located CU来缩放运动矢量。 用于推导位于同一位置的 CU 的参考帧列表和参考索引会被写入slice header中。 时域Merge候选的缩放运动向量如图 6中的虚线所示,它是从 co-located CU 的运动向量缩放的。
图6
如图 7 所示,在候选 C0 和 C1 之间选择时域候选的位置。如果位置 C0 处的 CU 不可用、被帧内编码或位于当前 CTU 行之外,则使用位置 C1。 否则,在时域Merge候选的推导中使用位置 C0。
图7
2. 3 HMVP候选
在 HEVC 中,有两种类型的 MVP,即时域 MVP 和空域 MVP,它们利用来自空间相邻或时间块的运动信息。在 VVC 中,引入了一种新型 MVP,即 基于历史的 MVP(HMVP)。 HMVP 的基本思想是进一步使用先前编码的 MV 作为 MVP,这些 MV 与相对于当前块的相邻或不相邻块相关联。为了跟踪可用的 HMVP 候选者,在编码器和解码器处都维护了一个 HMVP 候选者表,并动态更新。每当新的 CTU 行开始时,表就会重置以简化并行编码。
HMVP 表中最多有5个候选者。在对一个不处于子块模式(包括仿射模式)或 GPM 的帧间预测块进行编码之后,通过将关联的运动信息附加到表的末尾作为新的 HMVP 候选者来选择性地更新表。应用受限的先进先出 (FIFO) 规则来管理表,其中首先应用冗余检查以查找表中是否存在相同的HMVP。 如果找到,则从表中删除相同的 HMVP,然后将所有 HMVP 候选向前移动,并将相同的 HMVP 插入到表的最后一个条目中。使用 HMVP,即使编码块在空间上不与当前块相邻,先前编码块的运动信息也可以用于更有效的运动矢量预测。
为了减少冗余校验操作的数量,引入了以下简化:
表中的最后两个条目分别对 A1 和 B1 空域候选进行冗余检查。
一旦可用Merge候选的总数达到最大允许Merge候选减1,则终止来自HMVP的Merge候选列表构建过程。
2.4 Pair-wise average merge candidates derivation
VVC 中的Pair-wise average Merge候选取代了 HEVC 中的组合双预测Merge候选。Pair-wise average 候选是通过使用前两个Merge候选对现有Merge候选列表中预定义的候选对进行平均来生成的。 第一个Merge候选定义为 p0Cand,第二个Merge候选定义为 p1Cand。 根据 p0Cand 和 p1Cand 的运动向量的可用性分别计算每个参考列表的平均运动向量。 如果两个运动矢量都在一个列表中,则即使它们指向不同的参考帧,这两个运动矢量也会被平均,并将其参考图片设置为p0Cand之一; 如果只有一个运动矢量可用,则直接使用一个; 如果没有可用的运动矢量,则保持此列表无效。 此外,如果 p0Cand 和 p1Cand 的半像素插值滤波器索引不同,则将其设置为 0。
当添加Pair-wise average Merge候选后Merge列表未满时,则将向列表添加零运动候选以填充列表。
2.5 VTM代码分析
删去了代码中和GDR相关的和一些不重要的内容。
空域 :代码里的符号和上面图中的符号不一致,但是仔细看顺序还是一样的。
// above
const PredictionUnit *puAbove = cs.getPURestricted(posRT.offset(0, -1), pu, pu.chType);
bool isAvailableB1 = puAbove && isDiffMER(pu.lumaPos(), posRT.offset(0, -1), plevel) && pu.cu != puAbove->cu && CU::isInter(*puAbove->cu);
if (isAvailableB1)
{
miAbove = puAbove->getMotionInfo(posRT.offset(0, -1));
// get Inter Dir
mrgCtx.interDirNeighbours[cnt] = miAbove.interDir;
mrgCtx.useAltHpelIf[cnt] = miAbove.useAltHpelIf;
// get Mv from Above
mrgCtx.bcwIdx[cnt] = (mrgCtx.interDirNeighbours[cnt] == 3) ? puAbove->cu->bcwIdx : BCW_DEFAULT;
mrgCtx.mvFieldNeighbours[cnt << 1].setMvField(miAbove.mv[0], miAbove.refIdx[0]);
if (slice.isInterB())
{
mrgCtx.mvFieldNeighbours[(cnt << 1) + 1].setMvField(miAbove.mv[1], miAbove.refIdx[1]);
}
cnt++;
}
//left
const PredictionUnit* puLeft = cs.getPURestricted(posLB.offset(-1, 0), pu, pu.chType);
const bool isAvailableA1 = puLeft && isDiffMER(pu.lumaPos(), posLB.offset(-1, 0), plevel) && pu.cu != puLeft->cu && CU::isInter(*puLeft->cu);
if (isAvailableA1)
{
miLeft = puLeft->getMotionInfo(posLB.offset(-1, 0));
if (!isAvailableB1 || (miAbove != miLeft))
{
// get Inter Dir
mrgCtx.interDirNeighbours[cnt] = miLeft.interDir;
mrgCtx.useAltHpelIf[cnt] = miLeft.useAltHpelIf;
mrgCtx.bcwIdx[cnt] = (mrgCtx.interDirNeighbours[cnt] == 3) ? puLeft->cu->bcwIdx : BCW_DEFAULT;
// get Mv from Left
mrgCtx.mvFieldNeighbours[cnt << 1].setMvField(miLeft.mv[0], miLeft.refIdx[0]);
if (slice.isInterB())
{
mrgCtx.mvFieldNeighbours[(cnt << 1) + 1].setMvField(miLeft.mv[1], miLeft.refIdx[1]);
}
cnt++;
}
}
// above right
const PredictionUnit *puAboveRight = cs.getPURestricted( posRT.offset( 1, -1 ), pu, pu.chType );
bool isAvailableB0 = puAboveRight && isDiffMER( pu.lumaPos(), posRT.offset(1, -1), plevel) && CU::isInter( *puAboveRight->cu );
if( isAvailableB0 )
{
miAboveRight = puAboveRight->getMotionInfo( posRT.offset( 1, -1 ) );
if( !isAvailableB1 || ( miAbove != miAboveRight ) )
{
// get Inter Dir
mrgCtx.interDirNeighbours[cnt] = miAboveRight.interDir;
mrgCtx.useAltHpelIf[cnt] = miAboveRight.useAltHpelIf;
// get Mv from Above-right
mrgCtx.bcwIdx[cnt] = (mrgCtx.interDirNeighbours[cnt] == 3) ? puAboveRight->cu->bcwIdx : BCW_DEFAULT;
mrgCtx.mvFieldNeighbours[cnt << 1].setMvField( miAboveRight.mv[0], miAboveRight.refIdx[0] );
if( slice.isInterB() )
{
mrgCtx.mvFieldNeighbours[( cnt << 1 ) + 1].setMvField( miAboveRight.mv[1], miAboveRight.refIdx[1] );
}
cnt++;
}
}
//left bottom
const PredictionUnit *puLeftBottom = cs.getPURestricted( posLB.offset( -1, 1 ), pu, pu.chType );
bool isAvailableA0 = puLeftBottom && isDiffMER( pu.lumaPos(), posLB.offset(-1, 1), plevel) && CU::isInter( *puLeftBottom->cu );
if( isAvailableA0 )
{
miBelowLeft = puLeftBottom->getMotionInfo( posLB.offset( -1, 1 ) );
if( !isAvailableA1 || ( miBelowLeft != miLeft ) )
{
// get Inter Dir
mrgCtx.interDirNeighbours[cnt] = miBelowLeft.interDir;
mrgCtx.useAltHpelIf[cnt] = miBelowLeft.useAltHpelIf;
mrgCtx.bcwIdx[cnt] = (mrgCtx.interDirNeighbours[cnt] == 3) ? puLeftBottom->cu->bcwIdx : BCW_DEFAULT;
// get Mv from Bottom-Left
mrgCtx.mvFieldNeighbours[cnt << 1].setMvField( miBelowLeft.mv[0], miBelowLeft.refIdx[0] );
if( slice.isInterB() )
{
mrgCtx.mvFieldNeighbours[( cnt << 1 ) + 1].setMvField( miBelowLeft.mv[1], miBelowLeft.refIdx[1] );
}
cnt++;
}
}
// above left
if ( cnt < 4 )
{
const PredictionUnit *puAboveLeft = cs.getPURestricted( posLT.offset( -1, -1 ), pu, pu.chType );
bool isAvailableB2 = puAboveLeft && isDiffMER( pu.lumaPos(), posLT.offset(-1, -1), plevel ) && CU::isInter( *puAboveLeft->cu );
if( isAvailableB2 )
{
miAboveLeft = puAboveLeft->getMotionInfo( posLT.offset( -1, -1 ) );
if( ( !isAvailableA1 || ( miLeft != miAboveLeft ) ) && ( !isAvailableB1 || ( miAbove != miAboveLeft ) ) )
{
// get Inter Dir
mrgCtx.interDirNeighbours[cnt] = miAboveLeft.interDir;
mrgCtx.useAltHpelIf[cnt] = miAboveLeft.useAltHpelIf;
mrgCtx.bcwIdx[cnt] = (mrgCtx.interDirNeighbours[cnt] == 3) ? puAboveLeft->cu->bcwIdx : BCW_DEFAULT;
// get Mv from Above-Left
mrgCtx.mvFieldNeighbours[cnt << 1].setMvField( miAboveLeft.mv[0], miAboveLeft.refIdx[0] );
if( slice.isInterB() )
{
mrgCtx.mvFieldNeighbours[( cnt << 1 ) + 1].setMvField( miAboveLeft.mv[1], miAboveLeft.refIdx[1] );
}
cnt++;
}
}
}TMVP
if (slice.getPicHeader()->getEnableTMVPFlag() && (pu.lumaSize().width + pu.lumaSize().height > 12))
{
//>> MTK colocated-RightBottom
// offset the pos to be sure to "point" to the same position the uiAbsPartIdx would've pointed to
Position posRB = pu.Y().bottomRight().offset( -3, -3 );
const PreCalcValues& pcv = *cs.pcv;
Position posC0;
Position posC1 = pu.Y().center();
bool C0Avail = false;
bool boundaryCond = ((posRB.x + pcv.minCUWidth) < pcv.lumaWidth) && ((posRB.y + pcv.minCUHeight) < pcv.lumaHeight);
const SubPic& curSubPic = pu.cs->slice->getPPS()->getSubPicFromPos(pu.lumaPos());
if (curSubPic.getTreatedAsPicFlag())
{
boundaryCond = ((posRB.x + pcv.minCUWidth) <= curSubPic.getSubPicRight() &&
(posRB.y + pcv.minCUHeight) <= curSubPic.getSubPicBottom());
}
if (boundaryCond)
{
int posYInCtu = posRB.y & pcv.maxCUHeightMask;
if (posYInCtu + 4 < pcv.maxCUHeight)
{
posC0 = posRB.offset(4, 4);
C0Avail = true;
}
}
Mv cColMv;
int refIdx = 0;
int dir = 0;
unsigned arrayAddr = cnt;
bool existMV = (C0Avail && getColocatedMVP(pu, REF_PIC_LIST_0, posC0, cColMv, refIdx, false))
|| getColocatedMVP(pu, REF_PIC_LIST_0, posC1, cColMv, refIdx, false);
if (existMV)
{
dir |= 1;
mrgCtx.mvFieldNeighbours[2 * arrayAddr].setMvField(cColMv, refIdx);
}
if (slice.isInterB())
{
existMV = (C0Avail && getColocatedMVP(pu, REF_PIC_LIST_1, posC0, cColMv, refIdx, false))
|| getColocatedMVP(pu, REF_PIC_LIST_1, posC1, cColMv, refIdx, false);
if (existMV)
{
dir |= 2;
mrgCtx.mvFieldNeighbours[2 * arrayAddr + 1].setMvField(cColMv, refIdx);
}
}
if( dir != 0 )
{
bool addTMvp = true;
if( addTMvp )
{
mrgCtx.interDirNeighbours[arrayAddr] = dir;
mrgCtx.bcwIdx[arrayAddr] = BCW_DEFAULT;
mrgCtx.useAltHpelIf[arrayAddr] = false;
if (mrgCandIdx == cnt)
{
return;
}
cnt++;
}
}
}HMVP
bool PU::addMergeHMVPCand(const CodingStructure &cs, MergeCtx &mrgCtx, const int &mrgCandIdx,
const uint32_t maxNumMergeCandMin1, int &cnt, const bool isAvailableA1,
const MotionInfo miLeft, const bool isAvailableB1, const MotionInfo miAbove,
const bool ibcFlag, const bool isGt4x4
)
{
const Slice& slice = *cs.slice;
MotionInfo miNeighbor;
auto &lut = ibcFlag ? cs.motionLut.lutIbc : cs.motionLut.lut;
const int numAvailCandInLut = (int) lut.size();
for (int mrgIdx = 1; mrgIdx <= numAvailCandInLut; mrgIdx++)
{
miNeighbor = lut[numAvailCandInLut - mrgIdx];
if ( mrgIdx > 2 || ((mrgIdx > 1 || !isGt4x4) && ibcFlag)
|| ((!isAvailableA1 || (miLeft != miNeighbor)) && (!isAvailableB1 || (miAbove != miNeighbor))) )
{
mrgCtx.interDirNeighbours[cnt] = miNeighbor.interDir;
mrgCtx.useAltHpelIf [cnt] = !ibcFlag && miNeighbor.useAltHpelIf;
mrgCtx.bcwIdx[cnt] = (miNeighbor.interDir == 3) ? miNeighbor.bcwIdx : BCW_DEFAULT;
mrgCtx.mvFieldNeighbours[cnt << 1].setMvField(miNeighbor.mv[0], miNeighbor.refIdx[0]);
if (slice.isInterB())
{
mrgCtx.mvFieldNeighbours[(cnt << 1) + 1].setMvField(miNeighbor.mv[1], miNeighbor.refIdx[1]);
}
if (mrgCandIdx == cnt)
{
return true;
}
cnt ++;
if (cnt == maxNumMergeCandMin1)
{
break;
}
}
}
if (cnt < maxNumMergeCandMin1)
{
mrgCtx.useAltHpelIf[cnt] = false;
}
return false;
}pairwise-average candidates
if (cnt > 1 && cnt < maxNumMergeCand)
{
mrgCtx.mvFieldNeighbours[cnt * 2].setMvField( Mv( 0, 0 ), NOT_VALID );
mrgCtx.mvFieldNeighbours[cnt * 2 + 1].setMvField( Mv( 0, 0 ), NOT_VALID );
// calculate average MV for L0 and L1 seperately
unsigned char interDir = 0;
mrgCtx.useAltHpelIf[cnt] = (mrgCtx.useAltHpelIf[0] == mrgCtx.useAltHpelIf[1]) ? mrgCtx.useAltHpelIf[0] : false;
for( int refListId = 0; refListId < (slice.isInterB() ? 2 : 1); refListId++ )
{
const short refIdxI = mrgCtx.mvFieldNeighbours[0 * 2 + refListId].refIdx;
const short refIdxJ = mrgCtx.mvFieldNeighbours[1 * 2 + refListId].refIdx;
// both MVs are invalid, skip
if( (refIdxI == NOT_VALID) && (refIdxJ == NOT_VALID) )
{
continue;
}
interDir += 1 << refListId;
// both MVs are valid, average these two MVs
if( (refIdxI != NOT_VALID) && (refIdxJ != NOT_VALID) )
{
const Mv &mvI = mrgCtx.mvFieldNeighbours[0 * 2 + refListId].mv;
const Mv &mvJ = mrgCtx.mvFieldNeighbours[1 * 2 + refListId].mv;
// average two MVs
Mv avgMv = mvI;
avgMv += mvJ;
avgMv.roundAffine(1);
mrgCtx.mvFieldNeighbours[cnt * 2 + refListId].setMvField( avgMv, refIdxI );
}
// only one MV is valid, take the only one MV
else if( refIdxI != NOT_VALID )
{
Mv singleMv = mrgCtx.mvFieldNeighbours[0 * 2 + refListId].mv;
mrgCtx.mvFieldNeighbours[cnt * 2 + refListId].setMvField( singleMv, refIdxI );
}
else if( refIdxJ != NOT_VALID )
{
Mv singleMv = mrgCtx.mvFieldNeighbours[1 * 2 + refListId].mv;
mrgCtx.mvFieldNeighbours[cnt * 2 + refListId].setMvField( singleMv, refIdxJ );
}
}
mrgCtx.interDirNeighbours[cnt] = interDir;
if( interDir > 0 )
{
cnt++;
}
}Zero Mv
uint32_t arrayAddr = cnt;
int numRefIdx = slice.isInterB() ? std::min(slice.getNumRefIdx(REF_PIC_LIST_0), slice.getNumRefIdx(REF_PIC_LIST_1))
: slice.getNumRefIdx(REF_PIC_LIST_0);
int r = 0;
int refcnt = 0;
while (arrayAddr < maxNumMergeCand)
{
mrgCtx.interDirNeighbours[arrayAddr] = 1;
mrgCtx.bcwIdx[arrayAddr] = BCW_DEFAULT;
mrgCtx.mvFieldNeighbours[arrayAddr << 1].setMvField(Mv(0, 0), r);
mrgCtx.useAltHpelIf[arrayAddr] = false;
if (slice.isInterB())
{
mrgCtx.interDirNeighbours[arrayAddr] = 3;
mrgCtx.mvFieldNeighbours[(arrayAddr << 1) + 1].setMvField(Mv(0, 0), r);
}
arrayAddr++;
if (refcnt == numRefIdx - 1)
{
r = 0;
}
else
{
++r;
++refcnt;
}
}
mrgCtx.numValidMergeCand = arrayAddr;代码和上文描述的是一致的,代码里包含了更多的细节,这里就不再讨论了。