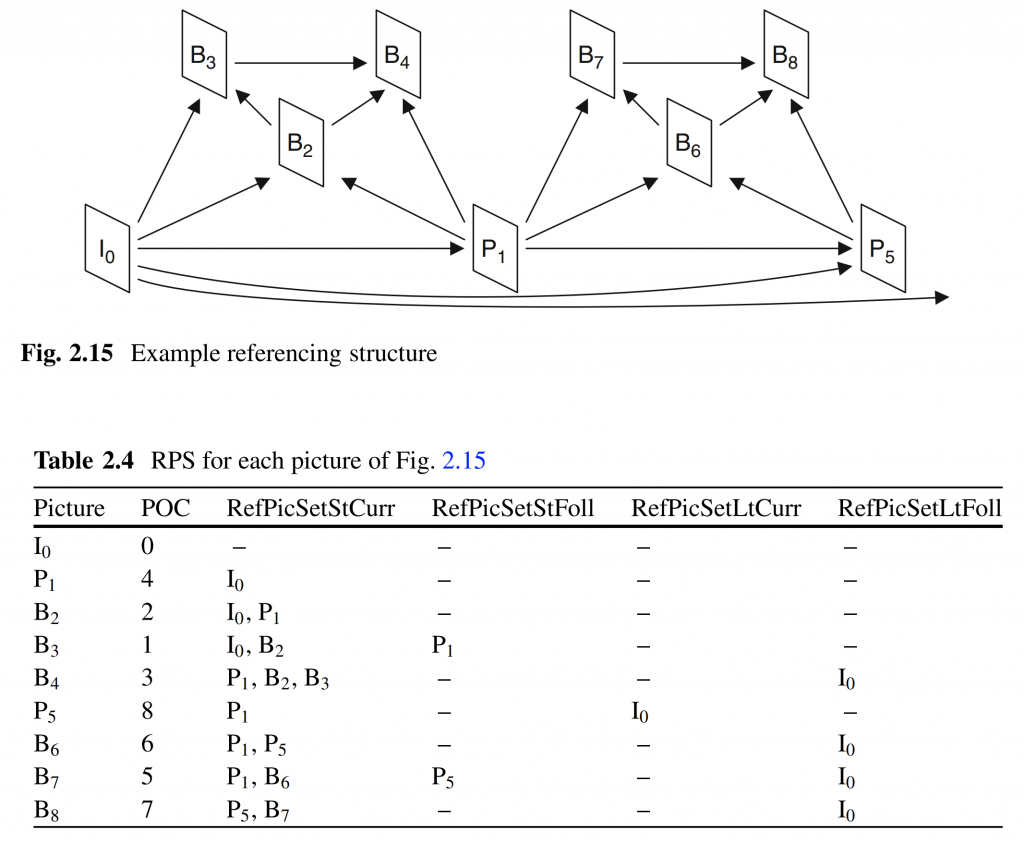
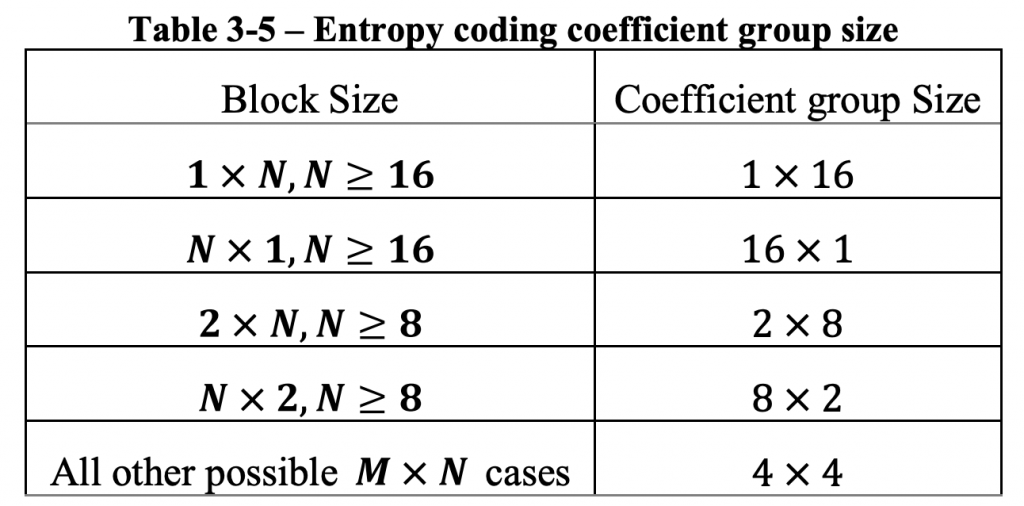
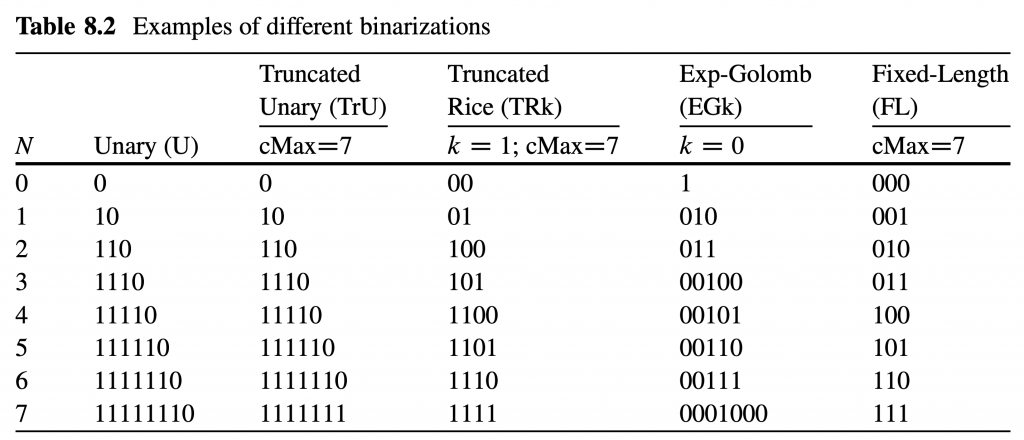
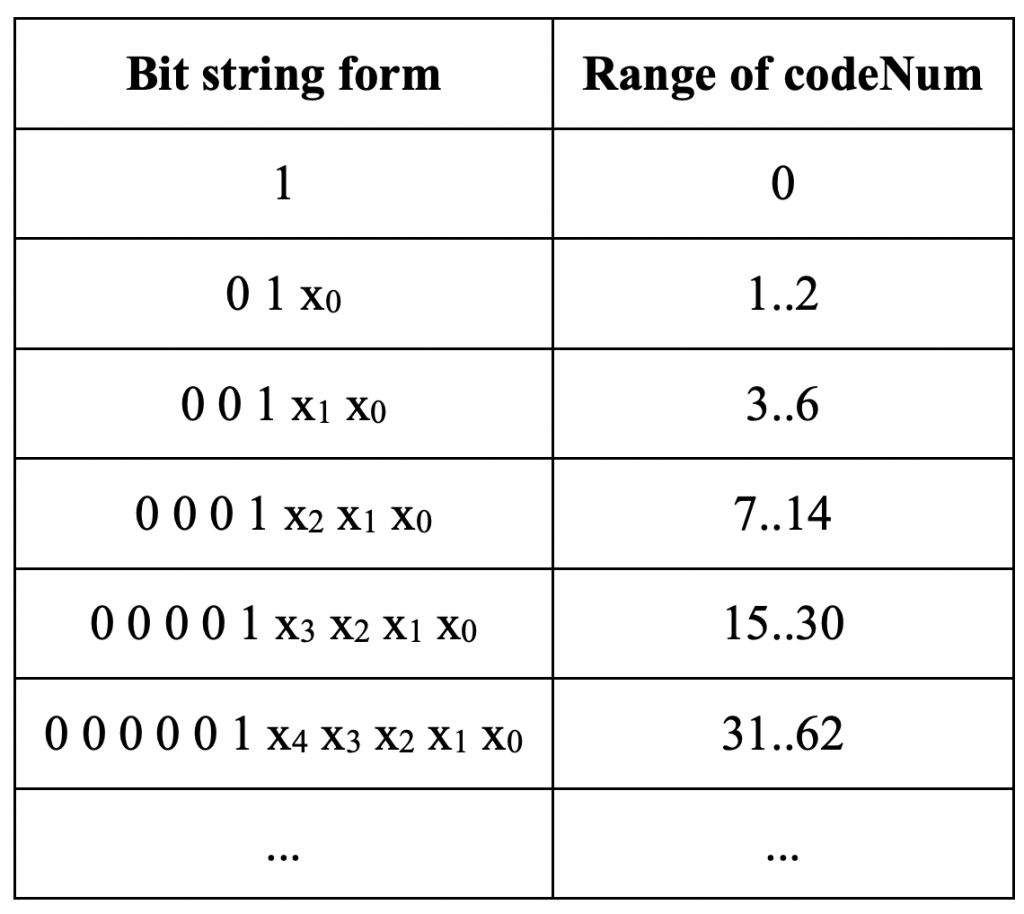
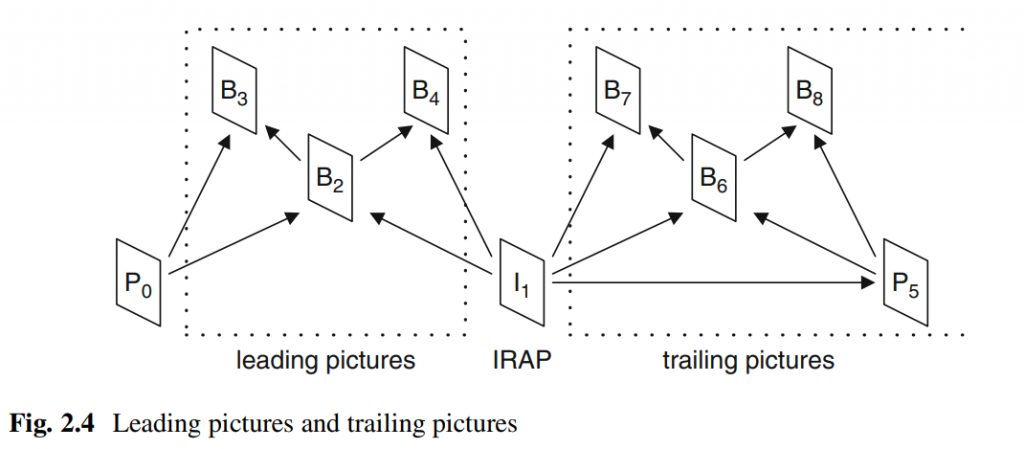
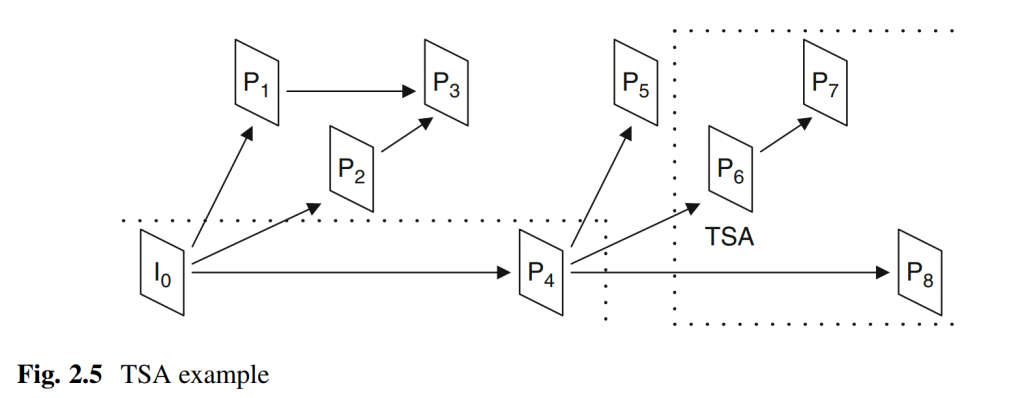
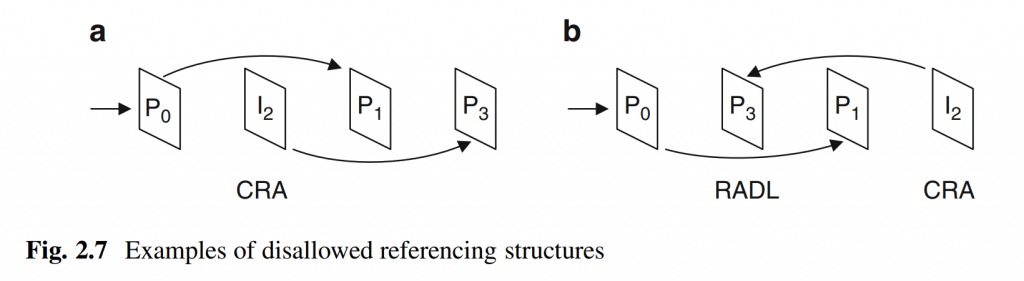
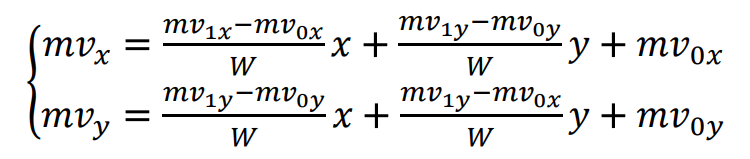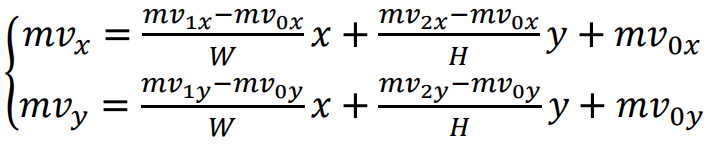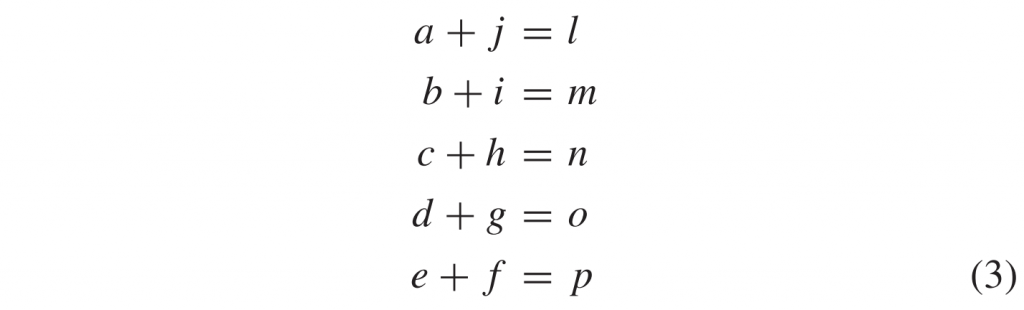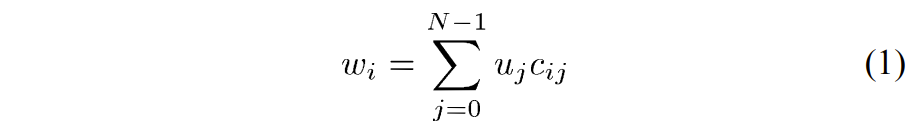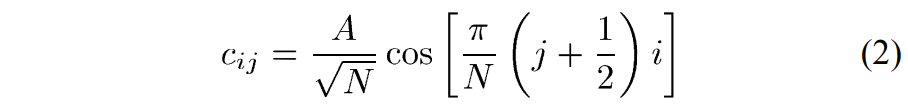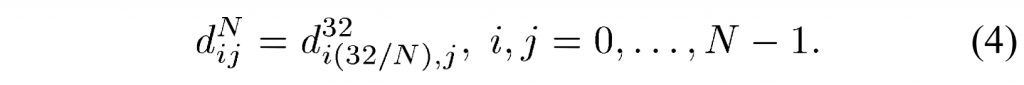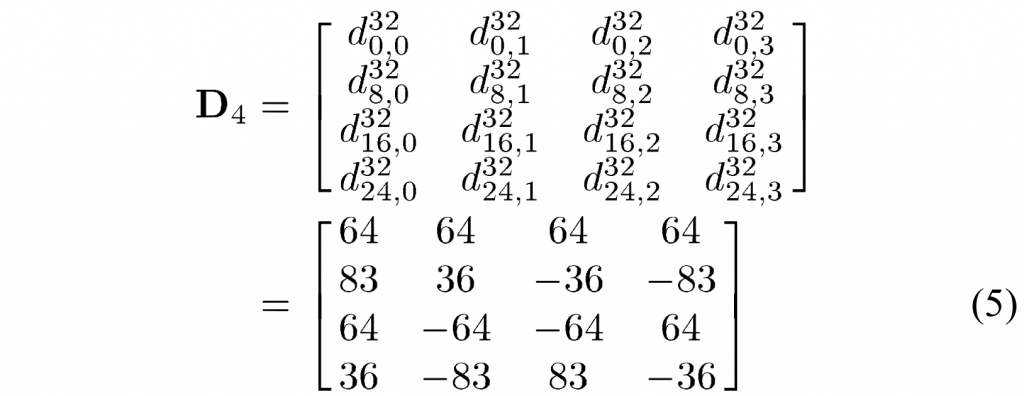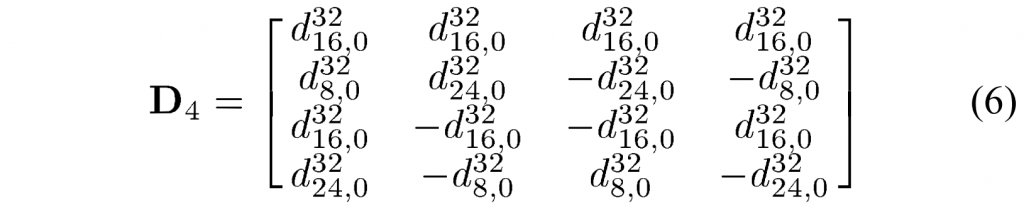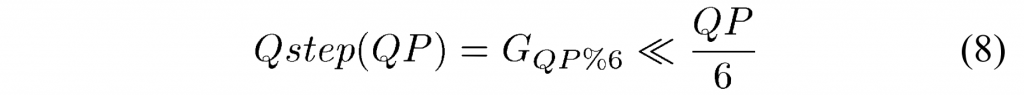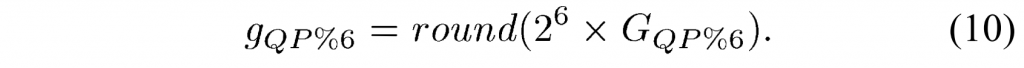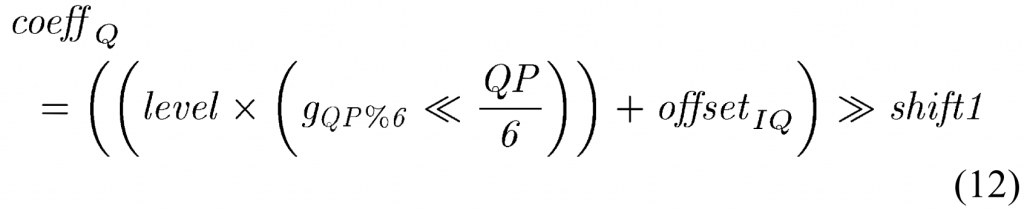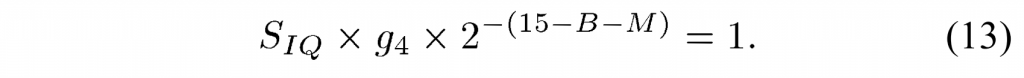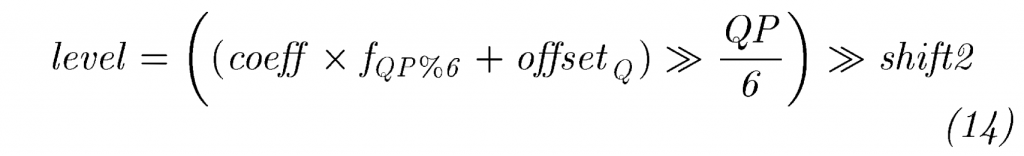H. Gao, S. Esenlik, E. Alshina, and E. Steinbach, “Geometric partitioning mode in versatile video coding: Algorithm review and analysis,” IEEE Trans. Circuits Syst. Video Technol., early access, Nov. 24, 2020
对于自然视频内容,矩形块划分对于 MCP (motion compensated prediction)来说不是最佳选择。 视频序列中图片的运动场通常由运动物体的边界来分割,如图2(a)和图2(b)所示。 这是因为对象通常表现出相对于静态背景或其他移动对象的移动,并且自然序列中的对象边界很少遵循矩形块图案。 如图2(c)所示,当使用矩形块来近似移动对象边界时,需要更精细的块划分,这增加了用于用信号通知这些块的划分和预测语法元素的速率开销。 此外,近似的分割边界很少遵循实际的运动场边界。 因此,预测误差更高,这增加了残差信令的比特率。
为了提高划分精度,基于分割的划分方法被集成到现有的视频编码标准结构中。 在基于分割的划分方法中,划分图是通过在编码器处对参考图片中的参考块应用分割算法来获得的。 在解码器处应用相同的分割算法以避免分割图的变换。 当前块被划分图分成多个分区,每个分区或者单独地与其关联的MV执行MCP或者从其他分区导出样本值。 可以向解码器发送额外的MV或者在解码器侧导出额外的MV以指示应用分割算法的参考块的位置。 尽管基于分割的分割方法很好地近似了对象的实际轮廓,但像素精确的分割算法显着增加了计算复杂性并导致硬件实现困难,特别是在解码器处。 此外,基于分割的分割方法无法有效地处理大块或包含由复杂纹理引起的多个边缘的块,例如图2(b)的左侧。
在 HEVC 和 VVC 的开发过程中,几何划分方案及其变体已在文献中提出并在核心实验 (CE) 中进行了研究。 几何划分方案旨在提高划分精度并最小化解码器端的计算复杂度和实现难度。 代替分割算法,使用一组预定义的直线将矩形块几何分割成两个分区,如图2(d)中的示例所示。 每个分区与其运动信息相关联并单独执行MCP。 运动信息和划分信息被发送到解码器。 该块由解码器侧解析的运动和划分信息直接重建。 因此,几何划分方案的解码器复杂度增加较小。
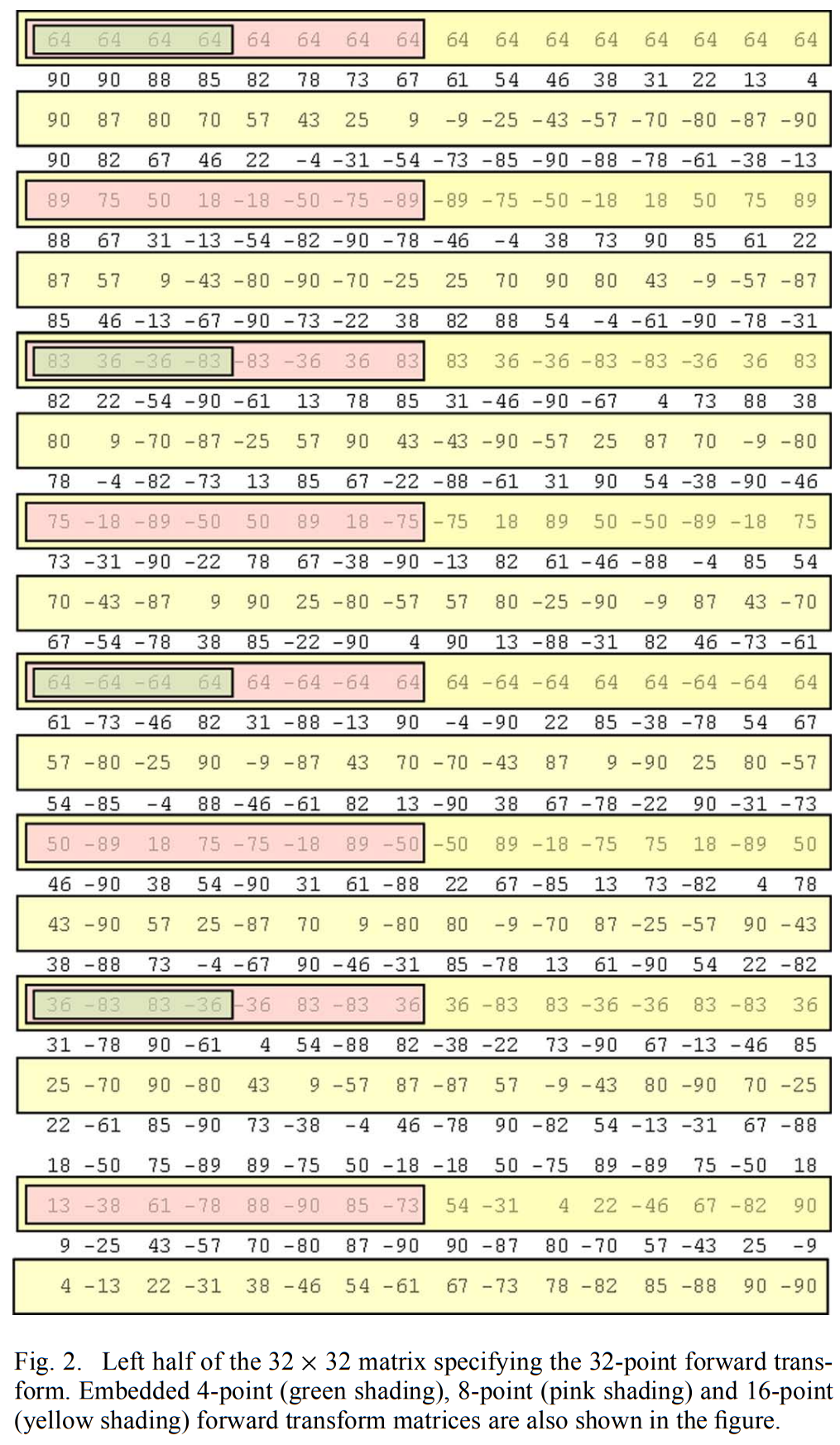
A. Core Algorithm of GPM in VVC
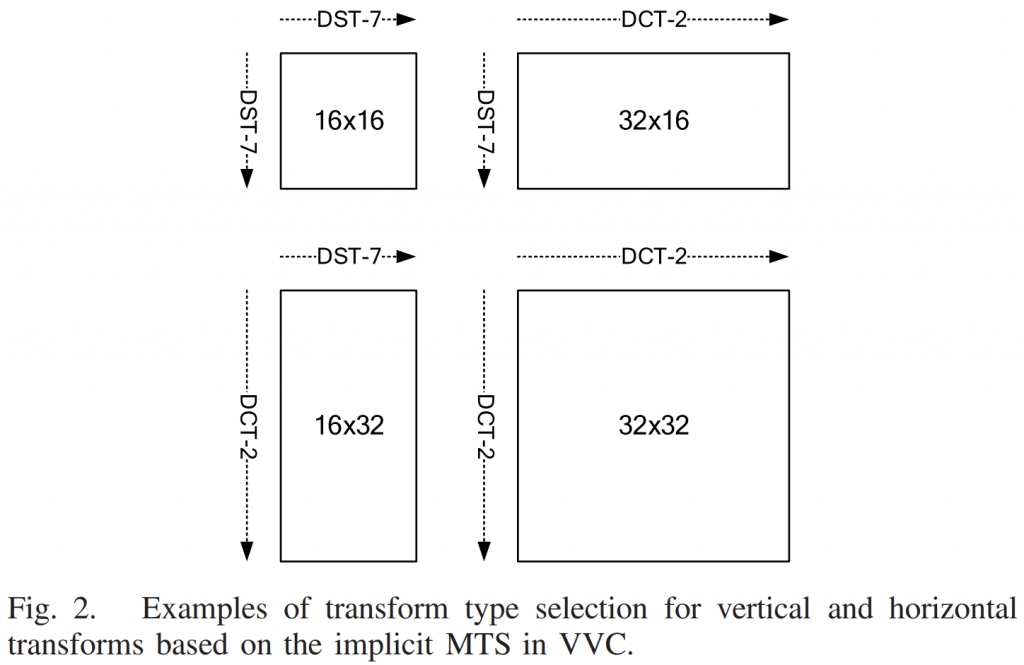
由于VVC中的帧内预测CU可以使用角度和非线性预测模式,非水平和非垂直边缘得到了很好的处理。 因此, GPM 重点关注帧间预测的 CU。 当GPM应用于CU时,该CU被直线划分边界分成两部分。 划分边界的位置在数学上由角度参数 \(\varphi\)和偏移参数 \(\rho\) 定义。 这些参数被量化并组合成GPM划分索引查找表。 当前CU的GPM划分索引被编码到比特流中。 总的来说,VVC 中的 GPM 支持 64 种划分模式,对于尺寸为 \(w\times h={2^k}\times2^l\)的亮度 CU,其中 \(k,l~\in~{3\ldots6}\)。 此外,GPM 在宽高比大于 4:1 或小于 1:4 的 CU 上被禁用,因为窄 CU 很少包含几何划分的图案。
两个 GPM 分区包含用于预测当前 CU 中相应部分的单独运动信息。 GPM 的每个部分只允许使用单向 MCP,因此 GPM 中 MCP 所需的内存大小等于常规双向 MCP 的大小带宽。 为了简化运动信息编码并减少GPM可能的组合,运动信息采用Merge模式进行编码。 GPM Merge候选列表源自传统的Merge候选列表,以确保仅包含单向运动信息。
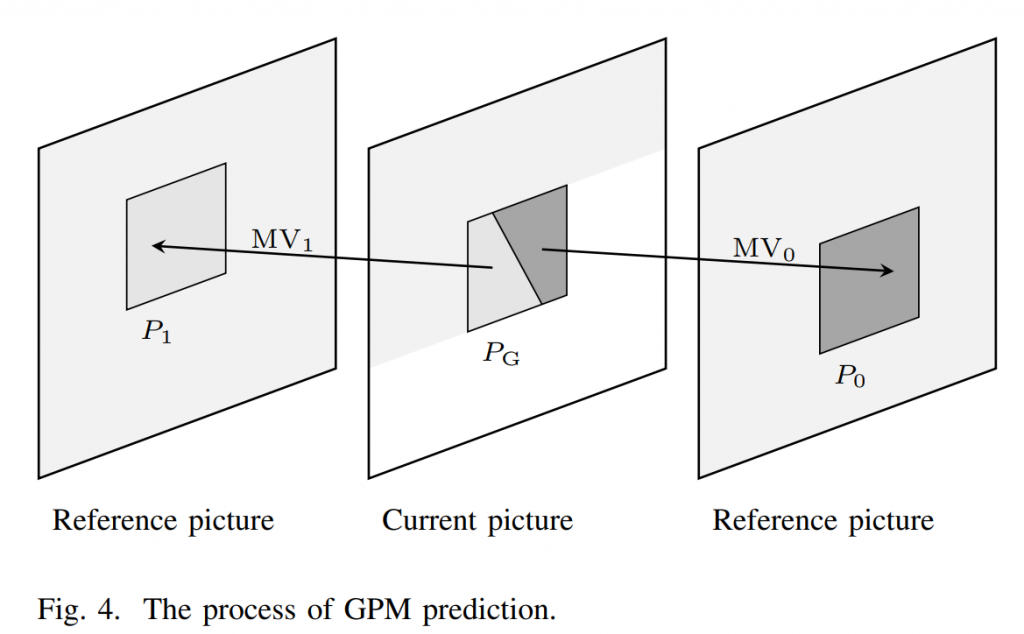
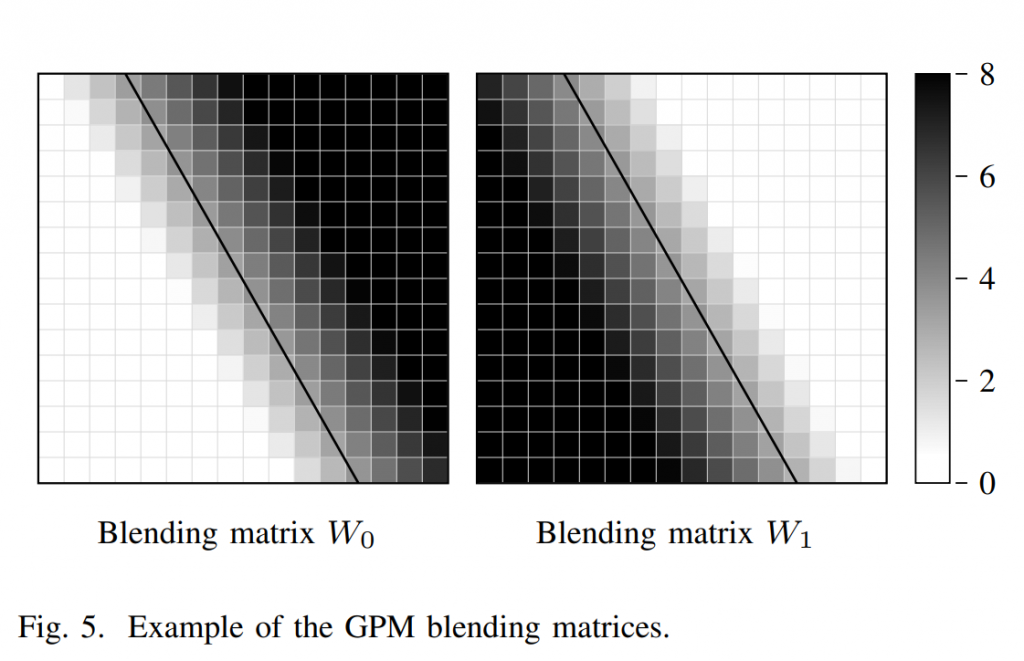
图4说明了GPM的预测过程。 当前CU的右侧预测部分(大小为w×h)由MV0从P0预测,而左侧部分由MV1从P1预测。 最终的 GPM 预测 PG 是通过使用整数混合矩阵 W0 和 W1 执行混合过程生成的,包含的权重范围为 0 到 8。这可以表示为(1):
\(P_{\mathrm{G}}=(W_0\circ P_0+W_1\circ P_1+4)\gg3\)
其中(2):
\(W_0+W_1=8J_{w,h},\)
其中 Jw,h 是大小为 w × h 的矩阵。 混合矩阵的权重取决于样本位置和分区边界之间的位移。 图 5 显示了一组示例混合矩阵。 混合矩阵推导的计算复杂度极低,因此这些矩阵可以在解码器侧即时生成。
然后从原始信号中减去GPM预测的PG以生成残差。 使用常规 VVC 变换、量化和熵编码引擎将残差变换、量化并编码到比特流中。 在解码器侧,通过将残差添加到 GPM 预测 PG 来重建信号。 当残差可以忽略不计时,GPM 还支持Skip模式。
B. Partitioning Boundary Definition and Quantization
1)划分边界的定义:划分边界定义为几何上位于CU内部的直线。 这条直线的方程用 Hessian 范式表示为(3):
\(x_\mathrm{c}~\cos(\varphi)-y_\mathrm{c}~\sin(\varphi)+\rho=0\)
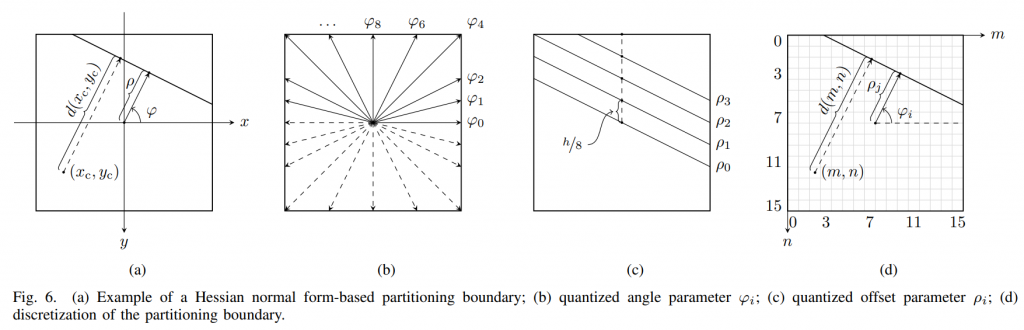
其中(xc,yc)定义与CU的中心位置相关的连续位置。 在图6(a)所示的示例中,(3)中的角度参数\(\varphi\)描述了从x轴到分割边界法向量的逆时针角度,而(3)中的偏移参数 \(\rho\) 是划分边界从CU中心定义的原点的位移。请注意,y轴被反转以简化分区边界的离散化。
任意位置(xc,yc)相对于分割边界的位移d用于导出混合矩阵W0和W1。 根据(3),d的值给出为(4):
\(d(x_\mathrm{c},y_\mathrm{c})=x_\mathrm{c}\mathrm{~}\cos(\varphi)-y_\mathrm{c}\mathrm{~}\sin(\varphi)+\rho.\)
由于位移是有方向的,因此 d 的值可以是正值或负值。 d 的符号表示位置 (xc, yc) 属于哪个分区,而 d 的大小等于 (xc, yc) 到分区边界的距离。
2)角度参数\(\varphi\)的量化:为了实现合理数量的定义的划分边界,必须对角度参数\(\varphi\)和偏移参数\(\rho\) 进行量化。 如图 6(b)所示,角度参数\(\varphi\)被量化为 20 个离散角度 \(\varphi_i\),范围 [0, 2π) 对称划分。 由于对角线或反对角线分割边界在 GPM 中最常用,因此量化的\(\varphi_i\)被设计为固定\(\tan(\varphi_i)\) 值,该值等于应用 GPM 的 CU 的可能长宽比。 例如,如果将 GPM 应用于宽高比 w/h = 1/2 的 CU,则对角线分区边界与由 \(\varphi_i~=~\arctan(1/2)\) 和 \(\rho=0\) 定义的 (3) 线对齐。 在所提出的 GPM 算法中,\(\tan(\varphi_i)\) 被限制为 {0, ±1/4, ±1/2, ±1, ±2, ∞} 中的值。 请注意,不包括产生接近水平划分边界的±4的正切值,因为运动场的接近水平划分不太频繁地用于自然视频内容。
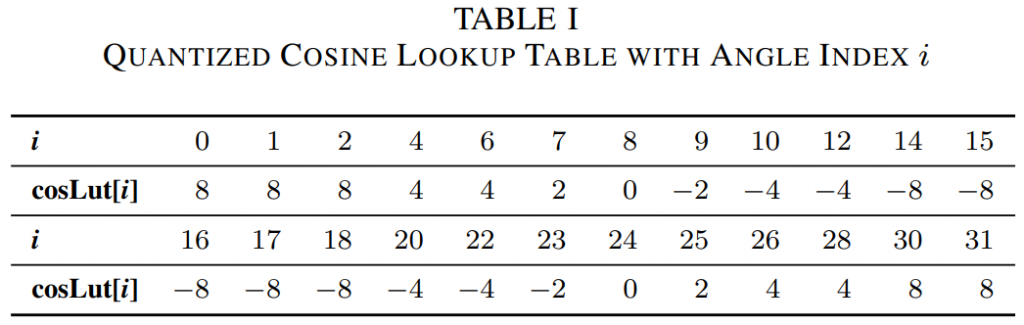
根据基于正切值的角度参数量化,(4) 中的 \(\cos(\varphi_i)\) 被离散化为表 1 所示的 3 位精度查找表。 cosLut[·] 的输入 i 是量化 \(\varphi_i\)的角度索引。 请注意,表 I 中的一些未使用的角度索引 i 值被跳过。 基于三角恒等式,\(sin\varphi_i\)的离散化查找表可以很容易地导出(5):
\(\operatorname{sinLut}[i]=-\operatorname{cosLut}[(i+8)\%32]\)
因此,(4)被重写为(6):
\(d(x_c,y_c)=(x_c\cdot cosLut[i])\gg3+(y_c\cdot cosLut[(i+8)\%32])\gg3+\rho\)
3)偏移参数\(\rho\)的量化:图6(c)示出了偏移参数\(\rho\)量化的示例。 根据CU宽度w和高度h,偏移参数\(\rho\)被量化为\(\rho_j\)。 偏移索引 j = {0 … 3}。 为了避免不同块大小之间分布不均匀的分区边界偏移,首先将 \(\rho_j\)分解为(7):
\(\rho_j=\rho_{x,j}\cos(\varphi_i)-\rho_{y,j}\sin(\varphi_i)\)
或(8):
\(\begin{aligned}\rho_j&=(\rho_{x,j}\cdot\cos\text{Lut}[i])\gg3\\&+(\rho_{y,j}\cdot\cos\text{Lut}[(i+8)\%32])\gg3.\end{aligned}\)
然后使用 ρx,j 和 ρy,j 与 w 和 h 耦合(9):
\(\rho_{x,j}=\begin{cases}0&i\%16=8\text{ or }(i\%16\neq0\text{ and }h\geqslant w)\\\pm j\cdot w/8&\text{otherwise}\end{cases}\)
和(10):
\(\rho_{y,j}=\begin{cases}\pm j\cdot h/8&i\%16=8\text{ or }(i\%16\neq0\text{ and }h\geqslant w)\\0&\mathrm{otherwise},\end{cases}\)
其中 j 是量化偏移 ρj 的偏移索引。 (9)和(10)中的ρx,j和ρy,j的符号表示偏移方向,如果角度索引i < 16,则将其设置为正,否则设置为负。 偏移参数量化后,式(6)改写为(11):
\(\begin{aligned}d(x_{\mathrm{c}},y_{\mathrm{c}})&=((x_{\mathrm{c}}+\rho_{x,j})\cdot cosLut[i])\gg3+((y_{\mathrm{c}}+\rho_{y,j})\cdot cosLut[(i+8)\%32])\gg3.\end{aligned}\)
表 II 中列出的几个冗余量化偏移在所提出的 GPM 算法中被删除。 因此,GPM 划分模式的总数为 \(N_\mathrm{GPM}~=~N_{\varphi}N_{\rho}~-~N_{\varphi}/2~-~2~-~4~=~64\) ,其中 Nψ = 20,Nρ = 4。GPM 划分模式如图 7 所示,按相同的角度索引 i 分组。 图 7 中的虚线划分线展示了未包含在所提出的 GPM 设计中的冗余模式。 支持的 64 种 GPM 分区模式由语法元素 merge_gpm_partition_idx 进行索引。
4)样本位置的离散化:为了避免GPM预测过程中的额外插值,P0和P1的整数位置在(1)中加权。 因此,混合矩阵 W0 和 W1 需要从基于整数位置的 d(m, n) 导出,其中 m, n ∈ Z ≥0,而不是从 d(xc, yc) 导出,其中 xc, yc ∈ R。 原点转移到图6(d)中的左上角,因为样本位置通常指的是VVC中CU的左上角样本。 因此,(11) 的完全离散形式由下式给出(12):
\(d(m,n)=((m+\rho_{x,j})\ll1-w+1)\cdot cosLut[i] +((n+\rho_{y,j})\ll1-h+1)\cdot cosLut[(i+8)\%32]\)
它用于生成混合矩阵 W0 和 W1 。 由于 cosLut[·] 为 3 位精度,且 m 和 n 左移一位,因此 d(m, n) 和 d(xc, yc) 的关系满足(13):
\(d(m,n)=\lfloor16d(x_\mathrm{c},y_\mathrm{c})+0.5\rfloor\)
请注意,在 (12) 中,d(m, n) 无需任何乘法即可实现,因为 cosLut[·] 中的值、ρx,j 中的 w/8 以及 ρy,j 中的 h/8 都是基于移位的值。 (12) 的无乘法设计的结果是 GPM 的编码器和解码器复杂度极低。
C. Blending Matrices of GPM
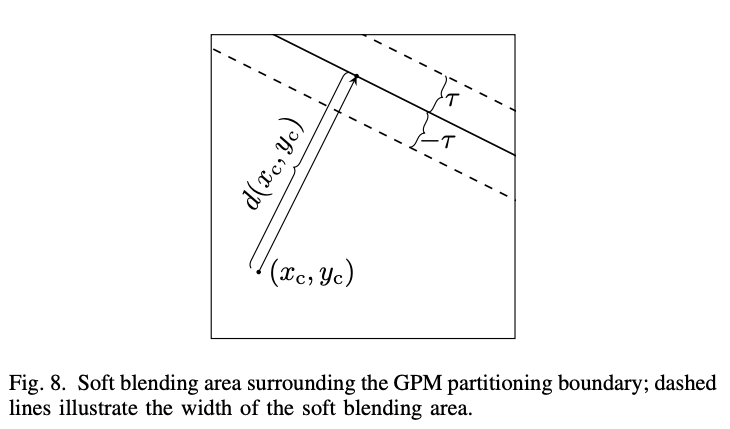
在提出的GPM算法中,应用了软的混合过程。 也就是说,如图8所示,当样品位于软混合区域内(即在虚线之间)时,使用(0,8)范围内的加权值倾斜; 否则,选择了0或8的完整加权值。 一个混合矩阵中单个样品位置的加权值由坡道函数给出(14):
\(\gamma_{x_c,y_c}=\begin{cases}0&d(x_c,y_c)\leqslant-\tau\\\frac{8}{2\tau}(d(x_c,y_c)+\tau)&-\tau<d(x_c,y_c)<\tau\\8&d(x_c,y_c)\geqslant\tau,&\end{cases}\)
τ定义混合区域的宽度。 在呈现的GPM算法中,选择τ作为两个样品。 基于(13)的τ= 2,(14)被离散为(15):
\(\gamma_{m,n}=\text{Clip}3(0,8,(d(m,n)+32+4)\gg3)\)
其中d(m, n)是根据(12)计算的。 然后,可以通过(2)轻松地计算其他混合矩阵的权重。 图5可视化一组混合矩阵的示例。 请注意,(2)和(15)用于生成Luma分量的混合矩阵,并且基于视频序列的颜色格式,简单地从Luma混合矩阵中进行了色度混合矩阵。
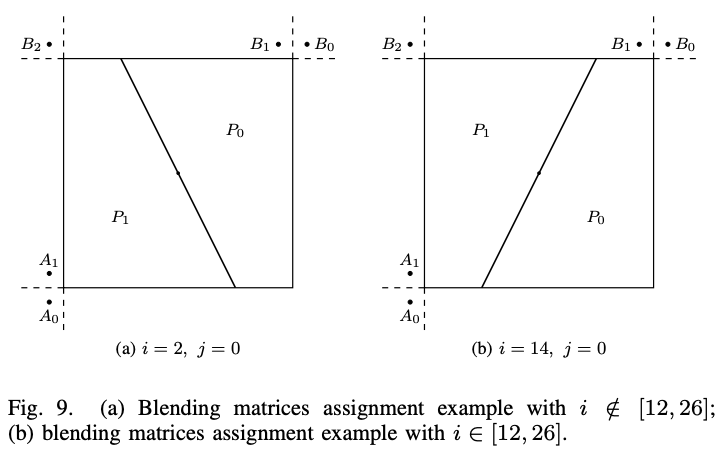
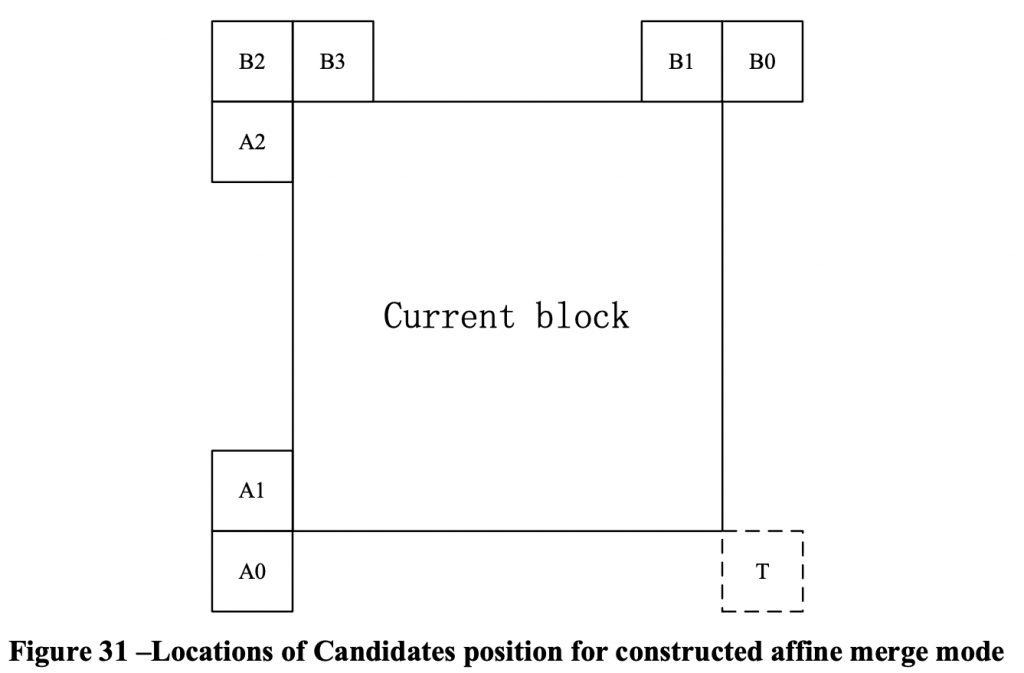
混合矩阵分配基于以下规则:如果角度索引i不在[12,26]的范围内,则将(15)的输出γm,n分配给与m∈{0…w – 1}和n∈{0…h – 1}的混合矩阵W0,而W1由(2)计算。 否则,如果角度索引i属于[12,26],则将γm,n分配给W1,而w0将推到出。 图9显示了解释这些规则的示例。 从常规Merge列表中得出的GPM Merge列表是通过在B1,A1,A1,B0,A0和B2的顺序上确定空间相邻CUS的运动信息来构建的。 熵编码期间,B1索引的code word通常最短。 当预测P0的运动信息由B1预测(即用最短的code word编码)时,GPM中运动信息的信号传输成本被最小化,因为P0的Merge索引在P1 Merge索引之前发出信号。 因此,在图9(a)的情况下,\(i\notin[12,26]\),(15)的γm,n分配给W0,而在图9(b)的情况下,γm,n分配给W1。
D. Motion Information Storage
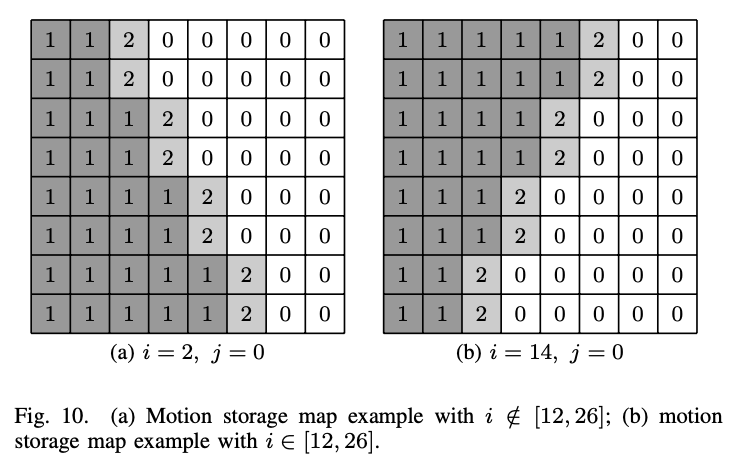
在VVC中,使用MCP后使用4×4样品粒度将CU的运动信息存储在缓存中。 存储的运动信息用于MV预测和合并列表的构建,或用于推导Deblocking滤波器的边界强度。 在VVC的常规MCP中,实际用于预测当前CU的运动信息被跨越并存储到4×4单元中。 但是,GPM涉及三种类型的运动信息。 也就是说,P0和P1包含其自己的单向MV,而混合区域则通过两者的运动信息进行物理预测。 因此,GPM的运动信息存储是基于分区的自适应设计的。
与混合矩阵派生类似,4×4单元的运动存储类型\(T\)由从本机的中心到划分边界的位移d确定。 在这里,使用(12)中的4×4单元的整数中心位置计算d,即(4M+2,4n+2)用m∈{0…w – 1}和n∈{0…h – 1}。 然后,该4×4单元的运动存储类型\(T\)为(16):
\(T_{4m,4n}=\begin{cases}1-A&d(4m+2,4n+2)\leqslant-32\\2&-32<d(4m+2,4n+2)<32\\A&d(4m+2,4n+2)\geqslant32,&\end{cases}\)
A 表示与混合矩阵对齐对齐的分区分配,由(17):
\(A=\begin{cases}1&i\in[12,26]\\0&otherwise.&\end{cases}\)
图10显示了具有角度索引\(i\notin[12,26]\)和\(i\in[12,26]\)的GPM运动存储图的示例。 t = 0或t = 1表示相应的4×4单元存储了用于预测P0或P1的单向运动信息,而带有t = 2的单元用于对两个单向运动组合的双向运动信息进行排序。 如果P0和P1的运动信息来自同一参考图片列表,则将双向运动信息设置为P1的运动信息。 请注意,GPM的运动存储过程通常与硬件实现中的混合过程并行执行,因此,通常在运动存储过程中重新计算d(4M+2, 4n+2),而不是重复使用d(m, n)来自混合矩阵推导。
E. GPM Merge List Derivation
GPM的运动信息通过Merge模式进行编码。 如前所述,GPM的每个部分仅使用单向运动信息,以避免GPM的MCP的其他内存占用。 但是,常规Merge列表可能包含直接从相邻CUS复制的单向或双向Merge候选。 由于双向Merge候选,常规Merge列表不能直接用作GPM Merge列表。
GPM Merge列表是通过GPM Merge索引的奇偶性从常规Merge列表中派生出来的。也就是说,对于具有GPM Merge索引的偶数值的候选者,使用来自具有对应的常规Merge索引的参考图片列表L0的MV0作为GPM Merge候选者。如果MV0不可用,则使用来自参考图片列表L1的MV1。相反,选择MV1作为GPM Merge索引的奇数值的默认GPM Merge候选,并且如果MV1不可用,则使用MV0。基于索引奇偶校验的方法直接从常规Merge列表中提取GPM Merge候选,而无需修剪,这将实现复杂性降至最低。
表III显示了GPM Merge列表推导的示例。 在表III(a)中所示的常规Merge列表的示例中,索引2和3的Merge候选中包含仅可用MV1的单向MVS,而其他Merge候选可以使用的是双向MVS。 相应的GPM Merge列表如表III(b)所示,MV1用于索引2的候选,因为默认MV0不可用。 GPM Merge候选者的其余部分是根据GPM Merge索引的奇偶校验从常规Merge列表中提取的。
F. Entropy Coding
GPM的几个语法元素使用熵编码被编码到位流中。 在高级语法HLS中,启用标志的GPM和GPM Merge候选者的最大数量在序列参数集SPS中编码。 GPM启用标志用固定长度代码进行编码,而GPM Merge候选者的最大数量相对于常规Merge候选者的最大数量,并用0-阶指数指数Golomb代码进行编码。
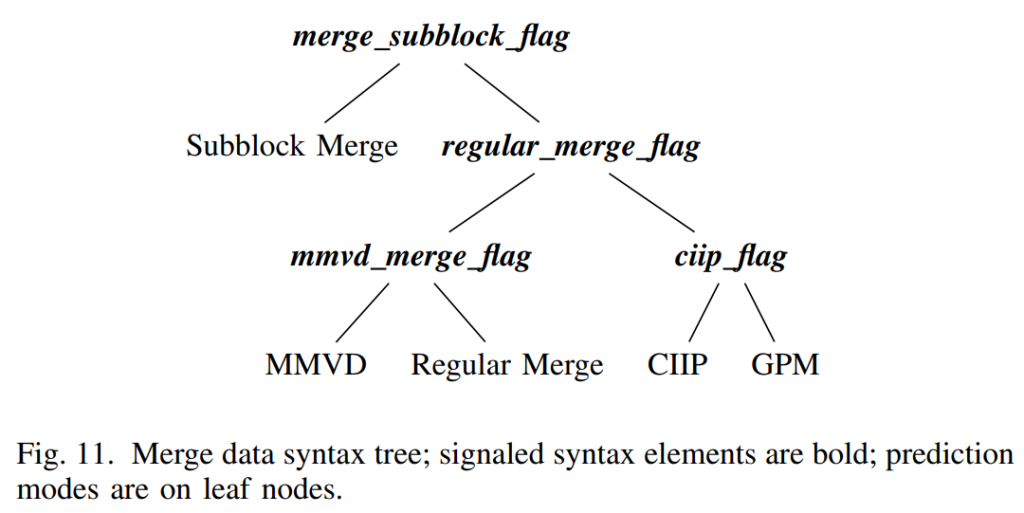
图11示出了Merge数据的语法树。 因为 GPM 模式是在Merge数据语法树的底部用信号通知的,所以在 CU 级别不需要 GPM 启用标志。 当获取的 ciip 标志为 0 并且满足 GPM 的应用条件时,GPM 隐式启用。
表IV是GPM的部分语法元素表。使用VVC的基于上下文的自适应二进制算术编码(CABAC)引擎对三个语法元素进行编码,包括GPM分区索引(merge_gpm_partition_idx)、P0的Merge索引(merge_gpm_idx0)和P1的Merge索引(merge_gpm_idx1)。由于merge_gpm_partition_idx是大致均匀分布的,因此使用固定长度代码对其进行二进制化,并使用CABAC的旁路模式(无上下文模型)对其进行编码,以简化编码过程,而merge_gpm_idx0和merge_gpm_idx1用0阶截断Rice码进行二进制化,并使用用相同的常规Merge索引初始值初始化的一个单个上下文模型进行编码。注意,所使用的GPM Merge索引GPM_idx0,1通过以下方式从用信号发送的语法元素导出(18):
\(\mathrm{GPM\_idx}_0=merge\_gpm\_idx0\)
和(19):
\(\begin{aligned}\text{GPM_idx}_1&=merge\_gpm\_idx1\\&+(merge\_gpm\_idx1\geqslant\text{GPM_idx}_0)?1:0,\end{aligned}\)
因为两个Merge索引不允许相同。
G. Encoder Search
所提出的 GPM 算法中应用了基于率失真优化 (RDO) 的编码器搜索。 与基于纹理的搜索方法相比,基于RDO的搜索更容易捕获包含相似纹理的几何分离的运动场。 此外,对于不同的视频内容,基于 RDO 的搜索比基于统计的方法更通用。
假设用信号发送的GPM Merge候选的最大数量是六,则每个划分模式总共具有6×5=30个运动信息组合,因为GPM_idx0和GPM_idx1不相同。 由于在 GPM 中设计了 NGPM = 64 划分模式,因此编码器将从 6 × 5 × 64 = 1920 个划分和运动信息的组合 GPM 候选中选择一个。 作为比较,在 VTM 7.0 中使用基于完全搜索的 RDO 对多达 6 × 5 × 2 = 60 个组合的 TPM 候选进行了详尽的测试。 组合的 GPM 候选者的数量对于 RDO 在编码器侧执行完整的混合和变换编码过程来说非常大。 为了降低 GPM 编码器搜索的计算复杂度,使用以下四个阶段确定最佳匹配 GPM 候选者:
Stage1:对于GPM Merge列表的每个单向运动信息候选,执行六个GPM Merge候选上的全CU MCP以获得与当前CU大小相同的六个矩形预测器。 预测变量和原始信号之间的亮度分量的绝对差之和 (SAD) 计算为 SADCU,k,其中索引 k ∈ {0 … 5}。 此阶段排除 GPM Merge候选列表中的相同条目。 如果Merge候选列表中的所有运动信息相同,则中止整个GPM编码器搜索。
Stage2:对于每个 GPM 划分模式,使用硬混合矩阵屏蔽掉由六个矩形预测器的 GPM_idx0 预测的部分(即,仅选择 0 或 8 作为权重值,具体取决于位移 d(m, n)的符号.)。 计算这些部分的亮度 SAD 并表示为 SADP0,k,l,其中 k = 0… 5 且 l = 0…63. 由于使用了硬混合矩阵(无混合区域),因此通过 GPM_idx1 预测的部分的 SAD 可以通过以下方式获得(20):
\(\mathrm{SAD}_{\text{P}1,k,l}=\mathrm{SAD}_{\text{CU},k}-\mathrm{SAD}_{\text{P}0,k,l}.\)
对于索引为 l 的划分模式,组合率失真 (RD) 成本 Jα,β,l 由下式给出(21):
\(J_{\alpha,\beta,l}=\text{SAD}_{\text{P}0,\alpha,l}+\text{SAD}_{\text{P}1,\beta,l}+\lambda(R_\alpha+R_\beta)\)
其中α和β表示预测指标GPM_idx0和GPM_idx1,Rα和Rβ表示相应的估计码率。 α 和 β 都属于 {0…5},但 α = β 的情况被排除在编码器搜索中。 GPM 候选按 Jα,β,l 排序。 此外,排除具有 Jα,β,l > SADCU,k +λRk 的 GPM 候选,其中 Rk 是第 k 个 GPM Merge候选的估计码率。
Stage3:第 2 阶段中最好的 60 个(或更少)组合 GPM 候选者用于进行软混合过程,以在亮度分量中生成 PG。 每个组合候选的 GPM 预测器 PG 和原始信号之间的亮度绝对变换差 (SATD) 之和计算为 SATDPG,l。 RD 成本更新为(22):
\(\begin{aligned}J’_{\alpha,\beta,l}&=\text{SATD}_{\text{PG},l}+\lambda(R_\alpha+R_\beta+R_l)\end{aligned}\)
其中Rl表示划分索引的估计码率。 GPM 候选者再次按 J’α,β,l 排序。 在此阶段,使用先前测试的编码工具(例如常规Merge或Affine)的最低 SATD 成本来提前终止。
Stage4:第 3 阶段中最好的八个(或更少)候选者的相应色度分量是通过软混合过程生成的。 对这些候选应用残差变换编码(如果存在残差)和基于 CABAC 的码率估计,以获得准确的码率成本 RGPM,其中包括运动码率、划分模式和残差编码。 这些候选信号与原始信号之间的三个分量的失真通过平方差之和 (SSD) 来测量,即 SSDPG,l。 最后,总体 RD 成本最低的 GPM 候选者(23):
\(J_{\alpha,\beta,l}^{\prime\prime}=\mathrm{SSD}_{\mathrm{PG},l}+\lambda R_{\mathrm{GPM}}\)
被选为最终的GPM模式。
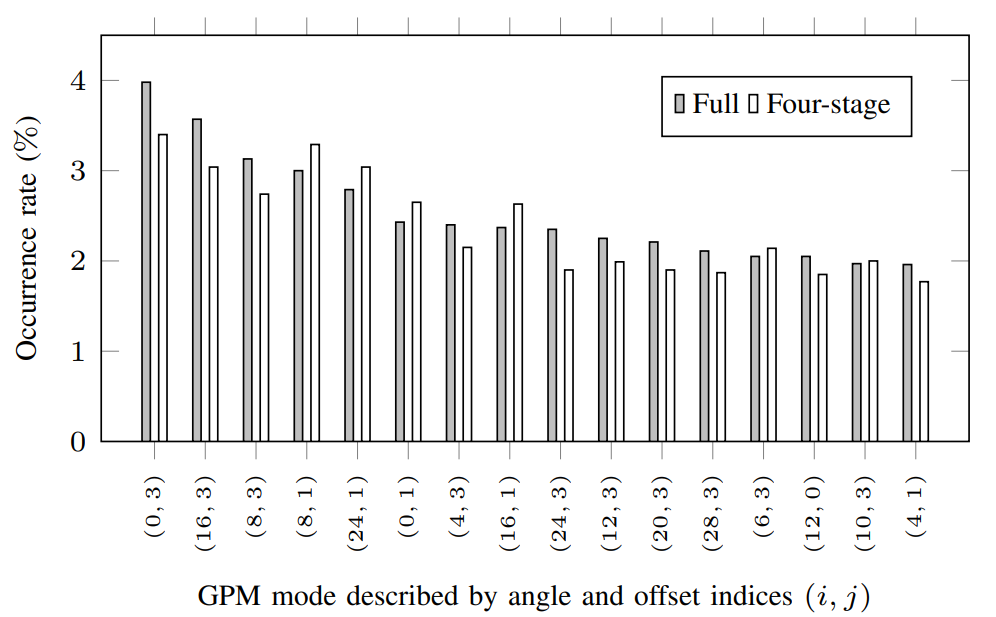
图 12 显示了全搜索中最常用的 16 种 GPM 模式以及这些模式在所提出的四阶段基搜索中的出现率。 可以看出,基于四阶段的搜索的发生率趋势与全搜索的发生率趋势相似,这表明基于四阶段的搜索可以以相对较低的编码器复杂度有效地保持编码性能。 注意,GPM的编码器搜索算法不限于所提出的基于四阶段的方法。 图 12 中呈现的统计数据可以用作其他编码器实现的指南。