- 初始化
- wpp=0和wpp1
- ivlCurrRange and ivlOffset,为什么ivlCurrRange要初始化成510
- IPB slice cabac state初始化值不一样,但是ctxidx的个数是一样的
- 二值化
- TR
- TB
- EGK
- FL
Matrix-Based Intra Prediction(MIP)
VVC的 MIP 模式代表了通过数据驱动方法设计的帧内预测器的新概念。整个MIP过程的概述如图6所示。W和H表示给定块的宽度和高度,MIP的输入由直接位于块上方的W个参考样本refT和直接位于块左侧的H个参考样本refL组成。从这个输入中,MIP帧内预测样本是通过应用平均化、矩阵矢量乘法和线性插值来生成的。

给定变换块上支持的MIP模式的数目nMIP对于mipSizeId=0为16,对于mipSize Id=1为8,对于mipSizeId=2为6。这里,对于4×4个块,mipSizeId设置为0,对于8×8个块和正好具有长度为4的一侧的块,mipSizeId设置为1,对于所有其他块,设置为2。每个MIP模式可以被转置,这是由标志mipTranspose确定的。
1) Averaging
在平均步骤中,上边界样本refT和左边界样本refL被减少到较小的边界redT和redL,对于4×4个块,boundarySize=2,对于所有其他块,boundarySize=4。如果W=boundarySize·2n,则redT定义为:
\(\operatorname{redT}[i]=(\sum_{j=0}^{2^n-1}\operatorname{refT}[2^n\cdot i+j]+(1\ll(n-1)))\gg n,\)
其中0≤i<boundarySize。类似地定义了左简化边界redL。两个边界redT和redL连接到单个简化边界pTemp。这里,如果模式没有转置,则先取redT,否则先取redL。为了减小其对于典型信号特征的幅度,pTemp被转换为一个向量通过
\(\text{p}[0]=2^{B-1}-\text{pTemp}[0];\quad\text{p}[i]=\text{pTemp}[i]-\text{pTemp}[0],\)
其中B表示比特深度,0<i<2·boundarySize。
2) Matrix Vector Multiplication
在第二步中,在缩减边界之外,通过矩阵向量多重叠加生成大小为predSize·predSize的缩减预测信号predMip,如果mipSizeId(W, H)∈{0,1},predSize(W, H))=4,否则predSize(W, H)=8。对于第k个MIP预测模式,0≤k<nMIP,计算(9)
\(\text{predMip}=(A_k\cdot\text{p+32}\cdot1)\gg6+\text{pTemp}[0]\cdot1.\)
在这个等式中,Ak是一个矩阵,其行数为predSize·predSize,列数等于p的大小。此外,“·”表示矩阵向量乘法,1表示大小为predSize.predSize的一个矩阵的向量,并且按元素应用右移。之后,对predMip的分量应用范围[0,2B−1)的clip。
如果水平和垂直上采样因子被设置为 upHor=W/predSize并且upVer=H/predSize,则信号predMip分别在块的每个upHor和upVer采样位置定义最终预测信号pred。更准确地说,如果 0≤x<predSize 和 0≤y<predSze,对于mipTranspose=0,pred定义为:
\(\begin{aligned}\text{pred}[(x+1)\cdot\text{upHor}-1,(y+1)\cdot\text{upVer}-1]\\=\text{predMip}[y\cdot\text{predSize }+x].\end{aligned}\)
对于mipTranspose=1,pred是通过交换最后一个方程右侧的x和y来定义的。
3) Linear Interpolation
在最后一个步骤中,在剩余的样本位置,通过线性插值导出pred的值,其中首先执行水平插值,然后执行垂直插值。这里,对于水平插值,通过参考样本将预测扩展到左侧。
4) Specification of the MIP Matrices
(9)中出现的每个矩阵Ak由 mipSizeId 和 MIP 模式 k 唯一地确定。其条目可以使用7位精度来表示。此外,对于mipSizeId=2,每个Ak的第一列是零,因为对应的MIP模式将恒定边界信号映射到相同值的恒定预测信号。因此,总的来说,为MIP指定了16个大小为16×4的矩阵,用于mipSizeId=0,8个大小为16*8的矩阵,用作mipSizeId=1,以及6个大小为64×7的矩阵,用来mipSizeId=2。
5) Computational Complexity and Memory Requirement of MIP
生成MIP预测所需的每个样本的平均乘法次数最多为四次,因此不大于VVC的传统帧内预测模式。因此,可以观察到,尽管MIP用于超过20%的帧内块,但不会产生任何解码器运行时开销。此外,根据前一节,存储所有MIP矩阵Ak的条目的总存储器需求为4144字节。
6) MIP as a Video-Coding Tool Designed by Data-Driven Methods
VVC中MIP模式的最终设计可以被视为最初提出的基于神经网络的帧内预测模式的低复杂度变体。虽然数据驱动训练算法的关键方面也被用于确定矩阵Ak的参数,但最终用于VVC的设计代表了与初始变体不同的增益复杂度权衡的操作点。复杂度降低的中心步骤是预测的输入的下采样和输出的上采样。通过这种方式,矩阵的大小可以显著减小,并且相同的矩阵可以用于不同的块形状。
编译反馈优化(PGO)
PGO(Profile-guided optimization)通常也叫做 FDO(Feedback-directed optimization),它是一种编译优化技术,它的原理是编译器使用程序的运行时 profiling 信息,生成更高质量的代码,从而提高程序的性能。
传统的编译器优化通常借助于程序的静态分析结果以及启发式规则实现,而在被提供了运行时的 profiling 信息后,编译器可以对应用进行更好的优化。通常来说编译反馈优化能获得 10%-15% 的性能收益,对于特定特征的应用(例如使用编译反馈优化 Clang本身)收益高达 30%。
编译反馈优化通常包括以下手段:
- Inlining,例如函数 A 频繁调用函数 B,B 函数相对小,则编译器会根据计算得出的 threshold 和 cost 选择是否将函数 B inline 到函数 A 中。
- ICP(Indirect call promotion),如果间接调用(Call Register)非常频繁地调用同一个被调用函数,则编译器会插入针对目标地址的比较和跳转指令。使得该被调用函数后续有了 inlining 和更多被优化机会,同时增加了 icache 的命中率,减少了分支预测的失败率。
- Register allocation,编译器能使用运行时数据做更好的寄存器分配。
- Basic block optimization,编译器能根据基本块的执行次数进行优化,将频繁执行的基本块放置在接近的位置,从而优化 data locality,减少访存开销。
- Size/speed optimization,编译器根据函数的运行时信息,对频繁执行的函数选择性能高于代码密度的优化策略。
- Function layout,类似于 Basic block optimization,编译器根据 Caller/Callee 的信息,将更容易在一条执行路径上的函数放在相同的段中。
- Condition branch optimization,编译器根据跳转信息,将更容易执行的分支放在比较指令之后,增加icache 命中率。
- Memory intrinsics,编译器根据 intrinsics 的调用频率选择是否将其展开,也能根据 intrinsics 接收的参数优化 memcpy 等 intrinsics 的实现。
编译器需要 profiling 信息对应用进行优化,profile 的获取通常有两种方式:
- Instrumentation-based(基于插桩)
- Sample-based(基于采样)
Instrumentation
Instrumentation-based PGO 的流程分为三步骤:
- 编译器对程序源码插桩编译,生成插桩后的程序(instrumented program)。
- 运行插桩后的程序,生成 profile 文件。
- 编译器使用 profile 文件,再次对源码进行编译。

Instrumentation-based PGO 对代码插桩包括:
1. 插入计数器(counter)
- 对编译器 IR 计算 MST,计算频繁跳转的边,对不在 MST 上的边插入计数器,用于减少插桩代码对运行时性能的影响。
- 在函数入口插入计数器。
2. 插入探针(probes)
- 收集间接函数调用地址(indirect call addresses)。
- 收集部分函数的参数值。
Sampling
Sample-based PGO 的流程同样分为三步骤:
- 编译器对程序源码进行编译,生成带调试信息的程序(program with debug information)。
- 运行带调试信息的程序,使用 profiler(例如linux perf)采集运行时的性能数据。
- 编译器使用 profile 文件,再次对源码进行编译。
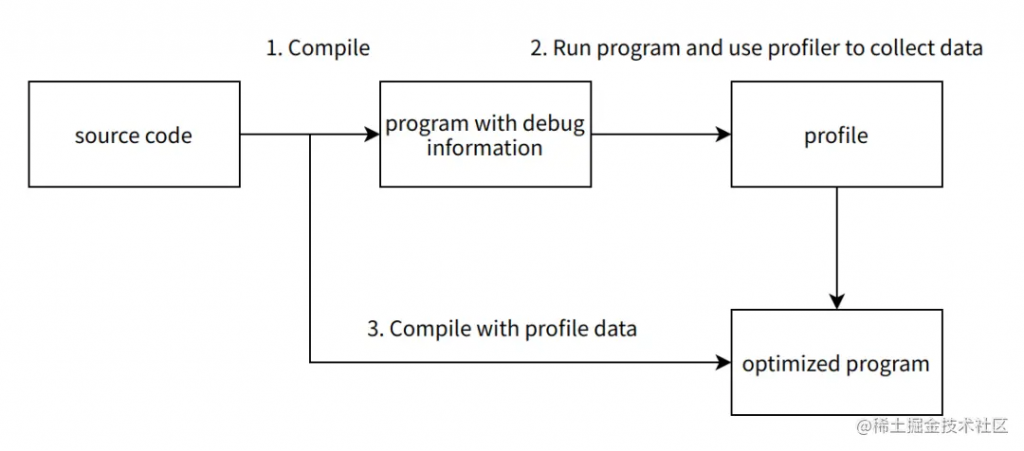
其中步骤2采集的数据为二进制级别采样数据(例如 linux perf 使用 perf record 命令收集得到 perf.data 文件)。二进制采样数据通常包含的是程序的 PC 值,我们需要使用工具,读取被采样程序的调试信息(例如使用 AutoFDO 等工具),将程序的原始二进制采样数据生成程序源码行号对应的采样数据,提供给编译器使用。
比较
对比 sampled-based PGO,Instrumentation-based PGO 的优点采集的性能数据较为准确,但繁琐的流程使其在业务上难以大规模落地,主要原因有以下几点:
- 应用二进制编译时间长,引入的额外编译流程影响了开发、版本发布的效率。
- 产品迭代速度快,代码更新频繁,热点信息与应用瓶颈变化快。而 instrumented-based PGO 无法使用旧版本收集的 profile 数据编译新版本,需要频繁地使用插桩后的最新版本收集性能数据。
- 插桩引入了额外的性能开销,这些性能开销会影响业务应用的性能特征,收集的 profile 不能准确地表示正常版本的性能特征,从而降低优化的效果,使得 instrumented-based PGO 的优点不再明显。
使用 Sample-based PGO 方案可以有效地解决以上问题:
- 无需引入额外的编译流程,为程序添加额外的调试信息不会明显地降低编译效率。
- Sample-based PGO 对过时的 profile 有一定的容忍性,不会对优化效果产生较大影响。
- 采样引入的额外性能开销很小,可以忽略不计,不会对业务应用的性能特征造成影响。
Adaptive Loop Filter (ALF)
Karczewicz, Marta, et al. “VVC in-loop filters.” IEEE Transactions on Circuits and Systems for Video Technology 31.10 (2021): 3907-3925.
A. Filter Shapes, Linear Filtering and Adaptive Clipping

ALF被应用于SAO的输出样本。亮度和色度分量分别支持7×7菱形和5×5菱形两种滤波器形状,如图2所示。在图2中,每个正方形对应于亮度或色度样本,中心正方形对应于待滤波的DC样本。为了减少信令开销和乘法次数,滤波器系数使用点对称。每个整数滤波器系数\(c_i\)用7-bit分数精度表示。此外,为了保持DC中性,一个滤波器的系数之和必须等于128,这是具有7-bit分数精度的1.0的定点表示(1):
\(\begin{aligned}2\sum_{i=0}^{N-2}c_i+c_{N-1}=128. & \left({\mathbf{1}}\right)\end{aligned}\)
在等式(1)中,对于 7 × 7 和 5 × 5 滤波器形状,系数 N 的数量分别等于 13 和 7。
通过将系数 \(c_i\) 应用于重构样本值 \(R(x, y)\)来导出坐标 (x, y) 处的滤波样本值 \(\tilde{R}(x,y)\),如下所示(2):
\(\begin{aligned}\tilde{R}(x,y)=&\left[\sum_{i=0}^{N-2}c_i\left(R\left(x+x_i,y+y_i\right)+R\left(x-x_i,y-y_i\right)\right) \\
+c_{N-1}R\left(x,y\right)+64\right]>>7,& \left({\mathbf{2}}\right)\end{aligned}\)
其中 \((x + x_i, y + y_i)\) 和 \((x − x_i, y − y_i)\) 是对应于第 i 个系数 \(c_i\) 的重构样本的坐标。 由于等式(1)的约束,等式(2)可以写为(3):
\(\begin{aligned}
\tilde{R}\left(x,y\right)& =R\left(x,y\right) \\
&+\left\{\left[\sum_{i=0}^{N-2}c_i\left(R\left(x+x_i,y+y_i\right)-R\left(x,y\right)\right)\right.\right. \\
&\left.+\sum_{i=0}^{N-2}c_i\left(R\left(x-x_i,y-y_i\right)-R\left(x,y\right)\right)+64\right] \\
&\left.>>7\right\}.& \left({\mathbf{3}}\right)
\end{aligned}\)
基于等式(3),通过将待滤波样本\(R(x, y)\)与其相邻样本之间的差的加权和添加到重构样本\(R(x, y)\)来获得滤波样本 \(\tilde{R}(x,y)\)。
等式(3)中的系数对于处于与待滤波样本相同的相对几何位置的所有样本是相同的。与仅考虑图片样本的几何接近度的线性滤波器不同,诸如双边滤波器的非线性滤波器也可以基于样本值的相似性来调整其系数。因此,双边滤波器可以在保留边缘的同时有效地去除噪声。为了允许ALF滤波器考虑样本之间的空间关系和值相似性,在等式(3)中添加clip相邻样本值和当前待滤波样本之间的差的可能性。当启用非线性ALF时,方程(3)修改如下:
\(\begin{aligned}
\tilde{R}\left(x,y\right)& =R\left(x,y\right) +\left[(\sum_{i=0}^{N-2}c_if_i+64)>>7 \right] & \left({\mathbf{4}}\right)
\end{aligned}\)
其中
\(\begin{aligned}f_i&=\min\left(b_i,\max\left(-b_i,R\left(x+x_i,y+y_i\right)-R\left(x,y\right)\right)\right)\\ &+\min\left(b_i,\max\left(-b_i,R\left(x-x_i,y-y_i\right)-R\left(x,y\right)\right)\right) & \left({\mathbf{5}}\right)\end{aligned}\)
\(b_i\)是由clipping索引\(d_i\)确定的系数\(c_i\)的clipping参数。\(b_i\)推导如下:
\(\left.b_i=\left\{\begin{array}{ll}2^{BD},&\text{when }d_i=0\\2^{BD-1-2d_i},&\text{otherwise}\end{array}\right.\right.\left({\mathbf{6}}\right)\)
其中BD是样本比特深度,\(d_i\)可以是0、1、2或3。
B. Luma Sub-Block Level Filter Adaptation
子块级滤波器自适应仅应用于亮度分量。每个4×4亮度块根据其方向性和2D拉普拉斯活动进行分类。首先,计算水平、垂直和两个对角线方向的样本梯度值:
\(\begin{aligned}
H_{k,l}=\left|2R\left(k,l\right)-R\left(k-1,l\right)-R\left(k+1,l\right)\right|, \\
V_{k,l}=\left|2R\left(k,l\right)-R\left(k,l-1\right)-R\left(k,l+1\right)\right|, \\
D0_{k,l}=\left|2R\left(k,l\right)-R\left(k-1,l-1\right)-R\left(k+1,l+1\right)\right|, \\
D1_{k,l}=\left|2R\left(k,l\right)-R\left(k-1,l+1\right)-R\left(k+1,l-1\right)\right|. & \left({\mathbf{7}}\right) \end{aligned} \)
基于样本梯度,子块水平梯度\(g_h\)、垂直梯度\(g_v\)和两个对角线梯度\(g_{d0}\)和\(g_{d1}\)计算如下:
\(\begin{aligned}
g_h=\sum_{k=i-2}^{i+5}+\sum_{l=j-2}^{i+5}H_{k,l}, \\
g_v=\sum_{k=i-2}^{i+5}+\sum_{l=j-2}^{i+5}V_{k,l}, \\
g_{d0}=\sum_{k=i-2}^{i+5}+\sum_{l=j-2}^{i+5}D0_{k,l}, \\
g_{d1}=\sum_{k=i-2}^{i+5}+\sum_{l=j-2}^{i+5}D1_{k,l},
& \left({\mathbf{8}}\right)\end{aligned}\)
索引\(i\)和\(j\)是指4×4亮度块中左上角样本的坐标。从等式(8)中可以看出,覆盖目标4×4块的10×10亮度窗口内的样本梯度之和用于对该块进行分类。为了降低复杂性,只计算10×10窗口中间隔样本的梯度,如图3所示。其他采样梯度的值设置为0。

其次,分配方向性D,子块水平和垂直梯度的最大值和最小值的比值:
\(g_{h,v}^{max}=max(g_h, g_v),g_{h,v}^{min}=min(g_h,g_v) \left({\mathbf{9}}\right)\)
以及两个子块对角线梯度的最大值和最小值之比:
\(g_{d0,d1}^{max}=max(g_{d0}, g_{d1}),g_{d0,d1}^{min}=min(g_{d0},g_{d1}) \left({\mathbf{10}}\right)\)
相互比较并且与一组阈值t1和t2进行比较:
步骤1:如果\(g_{h,v}^{max} \le t1\cdot g_{h,v}^{min}\)和\(g_{d0,d1}^{max} \le t1\cdot g_{d0,d1}^{min}\),D都设置为0(块被归类为“texture”)。
步骤2:如果\(g_{h,v}^{max} / g_{h,v}^{min}>g_{d0,d1}^{max} /g_{d0,d1}^{min}\),则在步骤3中计算方向性D,否则在步骤4中计算。。
步骤3:如果\(g_{h,v}^{max}>t2\cdot g_{h,v}^{min}\),D设置为2(块被归类为“强水平/垂直”),否则D设置为1(块被分类为“弱水平/垂直“)。
步骤4:如果\(g_{d0,d1}^{max}>t2\cdot g_{d0,d1}^{min}\),D设置为4(块被归类为“强对角线”),否则D设置为3(块被分类为“弱对角线”)。
只有在前面的步骤中没有分配给D的值的情况下,才执行上述D计算中的每个后续步骤。第三,活动值A计算为:
\(A=\left(\sum_{k=i-2}^{i+5}\sum_{l=j-2}^{j+5}\left(V_{k,l}+H_{k,l}\right)\right)>>\left(BD-2\right). \left({\mathbf{11}}\right)\)
A被进一步映射到0到4的范围:\(\hat A=Q_{min(A,15)}\),其中\(Q_n=\{0, 1, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3, 4\}\)。最后,每个4×4亮度块被分类为25类中的一类:
\(C=5D+\hat A \left({\mathbf{12}}\right)\)
每个类都可以分配自己的滤波器。

在对每个4×4亮度块进行滤波之前,根据表I中指定的子块梯度值,对滤波器系数应用几何变换,如90度旋转、对角线或垂直翻转,如图4所示。这相当于将这些变换应用于滤波器支持区域中的样本。目标是对齐不同块的方向性,以减少ALF类的数量,进而减少滤波器系数。应用几何变换允许具有水平边的4×4块和具有垂直边的4×4块都具有相同的方向性D。

C. Coding Tree Block Level Filter Adaptation
除了亮度4×4块级滤波器自适应外,ALF还支持CTB级滤波器自适应。亮度CTB可以使用为当前slice计算的滤波器集或者为已经编码的slice计算的一个滤波器集。它还可以使用16个离线训练的过滤器集中的一个。在每个亮度CTB内,所选滤波器集中的哪个滤波器应应用于每个4×4块,由该块的等式(12)中计算的类别C确定。
Chroma仅使用CTB级滤波器自适应。一个片中的色度分量最多可以使用8个滤波器。每个CTB可以选择这些过滤器中的一个。
D. Syntax Design
滤波器系数和clipping索引被携带在ALF APS中。ALF APS可以包括多达8个色度滤波器和一个具有多达25个滤波器的亮度滤波器组。对于25个亮度类别中的每一个,还包括索引\(i_C\)。具有相同索引\(i_C\)的类共享相同的滤波器。通过合并不同的类,减少了表示滤波器系数所需的比特数。滤波器系数的绝对值使用后面跟有非零系数的符号位的0阶Exp-Golomb码来表示。当clipping被启用时,还使用两位固定长度代码来用信号通知每个滤波器系数的clipping索引。APS内的ALF系数和clipping索引所需的存储最多为3480比特。解码器可以同时使用多达8个ALF APS。
滤波器控制语法元素包括两种类型的信息。首先,ALF开/关标志在序列、图片、Slice和CTB级别用信号通知。只有在相应级别启用亮度ALF时,才能在图片和切片级别启用色度ALF。第二,如果在图片、Slice和CTB级别启用ALF,则在该级别用信号通知滤波器使用信息。如果图片内的所有Slice都使用相同的APS,则参考ALF APS ID以Slice级别或图片级别进行编码。亮度分量可以参考多达7个ALF APS,色度分量可以参考1个ALF APS。对于亮度CTB,用信号通知指示使用哪个ALF APS或离线训练的亮度滤波器集的索引。对于色度CTB,索引指示使用参考APS中的哪个滤波器。
E. Line Buffer Reduction
为了减少ALF的存储需求,VVC采用了行缓冲边界处理。在VVC中,行缓冲器边界被放置在水平CTU边界之上的4个亮度样本和2个色度样本。当将ALF应用于行缓冲区边界一侧的样本时,不能使用行缓冲区边缘另一侧的样本。
图5给出了两个例子,其中4×4亮度块与行缓冲区边界相邻。当将ALF应用于图5(a)中的行E至H中的4×4亮度块时,如果没有行缓冲区边界处理,则需要使用DBF和SAO过滤的行B至K的样本。在较低的CTU可用之前,DBF和SAO过滤器不能应用于行A到D。因此,在没有行缓冲器的情况下,ALF不能应用于行E至H中的样本,直到较低的CTU可用为止。结果,除了行A到D之外,从E到K的7个亮度行将必须存储在用于亮度ALF的行缓冲器中。类似地,4个附加色度行将必须存储在色度ALF的行缓冲器中。

图5还说明了当对与行缓冲区边界相邻的4×4亮度块进行分类时样本梯度值的计算。为了计算与行缓冲区边界相邻的样本梯度值(标记为×),应用重复填充来替换无法使用的样本。例如,在图5(a)中,用行E中的样本替换行D中的样本。行缓冲区边界另一侧的所有样本梯度值都设置为0。由于我们将一些样本梯度值设置为0,从而减少了样本梯度的总和,因此方程(11)中的A推导按如下比例缩放:
\(A=\left(\sum_{k=i-2}^{i+5}\sum_{l=j-2}^{j+5}\left(V_{k,l}+H_{k,l}\right)\cdot 3 \right)>>\left(BD-1\right). \left({\mathbf{13}}\right)\)
行缓冲区边界滤波应用如图6所示的对称样本填充,其中p12标记待滤波样本,p0至p24是SAO之后的样本值,p’0至p’24是修改后的样本值。当待滤波样本的滤波器形状不越过行缓冲区边界时,在滤波过程中使用SAO之后的样本值。否则,将在滤波过程中使用修改后的值。与重复填充相比,对称样本填充已被证明可以产生不太明显的视觉伪影。然而,当要滤波的样本位于最靠近行缓冲区边界的行中时,如图6(a)所示,2D滤波器等效于水平滤波器,它仍然会引入明显的视觉伪影。

通过将滤波器强度减少8倍来最小化这些伪影,从而得出以下公式,其中等式(4)中的偏移7被偏移10代替:
\(\tilde{R}\left(x,y\right)=R\left(x,y\right)+\left[\left(\sum_{i=0}^{N-2}c_if_i+512\right)>>10\right]\)
F. ALF Encoder Design in VTM
这里描述VTM-9.0中的ALF编码器实现。编码器通过最小化率失真成本来计算ALF语法元素的值,所述率失真成本是失真的加权和,所述失真被测量为原始样本和应用ALF滤波器之后的样本之间的平方误差,以及传输ALF语法元素所需的比特数。滤波器系数是通过求解Wiener-Hopf方程来计算的。采用平方误差估计方法,允许在不执行实际滤波操作的情况下计算滤波失真。针对clipping 索引的所有可能组合收集计算滤波器系数和估计失真所需的统计信息。分别收集每个CTB的统计数据,在亮度成分的情况下,收集每个CTU的每个类别的统计数据。
1) 亮度分量:对于每个图片,基于该图片的统计信息,获得亮度分量的新滤波器集,表示为FY,D,如下所示:
(1) 编码器通过合并启用ALF的CTB的统计信息来导出滤波器集FY,D。在第一次迭代中,假设为所有CTB启用ALF。
(2) 基于使用导出的滤波器计算的速率失真成本和CTB的统计来为每个CTB确定是否应用ALF滤波器。
步骤1)和2)重复4次。
当设计在步骤1)中设置的亮度滤波器时,编码器首先为25个亮度类别中的每一个计算滤波器。然后将合并算法应用于这25个滤波器。在每次迭代中,通过合并两个滤波器,该算法将滤波器的数量减少1。为了确定应该合并哪两个滤波器,对于每对剩余的滤波器,编码器通过分别合并两个滤波器和相应的统计数据来重新设计滤波器。使用重新设计的滤波器,然后估计失真。编码器以最小的失真合并该对。获得25个滤波器组,第一组具有25个滤波器,第二组具有24个滤波器,以此类推,直到第25组包含单个滤波器。选择最小化率失真成本的集合,包括对滤波器系数进行编码所需的比特。
在设计滤波器时,迭代计算clipping 索引和N−1滤波器系数,直到平方误差不减小。在每次迭代中,clipping 索引的值都会逐一更新,从索引d0开始,一直到达到索引dN−2。更新索引时,最多测试3个选项:保持其值不变、增加1或减少1。针对这3个值计算滤波器系数和近似失真,并选择使平方误差最小化的值。在第一次迭代开始时,clipping 索引的值被初始化为2,或者当合并两个滤波器时,di的值被设置为这些滤波器的对应剪裁索引的平均值。
亮度分量还可以使用离线训练的滤波器集和可用ALF APS中携带的亮度滤波器集。通过访问APS,从最近发信号到最后一个,编码器获得多达7个亮度滤波器组,这些滤波器组表示为FiY,APS,其中i=0,。。。,NAPS−1。亮度ALF语法元素的最终值是通过选择滤波器集Fij的最佳组合来获得的,其中i=0,1和j=0,。。。,NAPS:
· 16个离线训练的滤波器集,
· FY,D,如果i=1,
· F0Y,APS ,…, Fj-1Y,APS, 如果j>0
2) 色度分量:基于当前图片统计,计算色度滤波器组FC,D。导出8个色度滤波器组,表示为FiC,D,其中i=1,2,。。。,7, 8.滤波器组FiC,D包含i个滤波器。滤波器组FiC,D如下获得:
1) 当前图片被均匀地划分为i个区域。对于每个区域,通过合并该区域中所有CTB的统计信息来计算色度滤波器。
2) 对于图片中的每个色度CTB,ALF开/关标志和来自集合FiC,D的滤波器索引被确定为最小化估计的速率失真成本。
3) FiC,D中的每个滤波器通过合并色度CTB的统计来重新设计,其中在步骤2)中为其选择了当前要重新设计的滤波器。
4) 步骤2)和3)重复i+1次。
选择使速率失真成本最小化的滤波器组FiC,D作为色度滤波器组FC,D。最后,编码器从可用的APS中选择FC,D或滤波器组之一,以用于色度分量。
Bi-Directional Optical Flow (BDOF)
传统的双向预测是来自先前编码的图片的两个预测块的加权组合。 两个MV用于分别从List0参考图片和List1参考图片获得两个预测块。 然而,由于基于块的MC的限制,两个预测块内的样本之间通常存在剩余位移。 BDOF 的目的是在原始块级 MV 之上补偿每个预测样本的精细位移。
与基于块的运动补偿相反,MV 的细化值不在 BDOF 中用信号表示。 BDOF应用于常规Merge模式中或非SMVD的帧间模式中的CU的亮度CB。 BDOF 仅限于宽度和高度大于或等于 8 个亮度样本且亮度样本数量大于或等于 128 的 CU。
BDOF 建立在光流概念的基础上。 令 I(i, j,t) 为样本在位置 (i, j) 和时间 t 处的亮度值。 假设物体运动过程中每个样本的亮度恒定,此时的光流微分方程可以表示为(1):
\(\begin{aligned}&0=\frac{\partial I}{\partial t}+v_x\frac{\partial I}{\partial x}+v_y\frac{\partial I}{\partial y}.\end{aligned}\)
如图 8 所示,在每个样本位置,描述从 Ic 到 I0 的剩余小位移的运动 (vx , vy ) 与其从 Ic 到 I1 的运动对称。 这里,Ic、I0 和 I1 分别是当前块以及来自列表 0 和列表 1 参考图片的两个预测块中的亮度值数组。 为了简单起见,假设相对于两个参考图片的剩余运动幅度相同且方向相反。 这一假设反映在只有当两个不同的参考图片在 POC 中与当前图片具有相等距离时才应用 BDOF 的约束。

基于对称运动模型,式(1)可用于从两个方向估计Ic中每个样本的值,一个来自I0中的对应A,另一个来自I1中的对应B。 (vx , vy ) 的值是通过最小化具有精细运动的两个预测之间的差异来计算的(2)(3):
\((v_x,v_y):\min\sum_{(i,j)\in\Omega}\Delta^2(i,j);\)
\(\begin{aligned}
\Delta\left(i,j\right)=& I_0(i,j)-I_1(i,j) \\
&+v_x(\frac{\partial I_0(i,j)}{\partial x}+\frac{\partial I_1(i,j)}{\partial x}) \\
&+v_y(\frac{\partial I_0(i,j)}{\partial y}+\frac{\partial I_1(i,j)}{\partial y}).
\end{aligned}\)
这里(i,j)是预测块内样本的空间坐标,Ω是该样本的区域。 对离散样本数组 I0(i, j) 和 I1(i, j) 进行空间导数的近似(4)(5):
\(\begin{aligned}\frac{\partial I_{0,1}(i,j)}{\partial x}&=(I_{0,1}(i+1,j)-I_{0,1}(i-1,j))\gg1\end{aligned}\)
\(\begin{aligned}\frac{\partial I_{0,1}(i,j)}{\partial y}&=(I_{0,1}(i,j+1)-I_{0,1}(i,j-1))\gg1\end{aligned}\)
为了降低推导局部剩余运动的计算复杂度,假设每个 4 × 4 子块内的向量 (vx , vy ) 恒定。 它计算一次并由子块中的所有样本共享。 此外,为了使导出的运动场更加稳定,每个 4 × 4 子块的 (vx , vy ) 是根据中心包含 4 × 4 子块的扩展 6 × 6 区域(在(2)中记为 Ω )计算的。
(2) 中的优化问题可以通过将两个偏导数设置为零来解决,所得线性方程组近似求解为(4)-(9):
\(\begin{aligned}v_x=-\frac{S_4}{S_1},\quad v_y=-\frac{S_5+v_xS_3}{S_2}\end{aligned}\)
\(\begin{aligned}S_1&=\sum_{(i,j)\in\Omega}\vartheta_x(i,j)\cdot\vartheta_x(i,j),\end{aligned}\)
\(\begin{aligned}S_2&=\sum_{(i,j)\in\Omega}\vartheta_y(i,j)\cdot\vartheta_y(i,j),\end{aligned}\)
\(\begin{aligned}S_3&=\sum_{(i,j)\in\Omega}\vartheta_x(i,j)\cdot\vartheta_y(i,j),\end{aligned}\)
\(\begin{aligned}S_4&=\sum_{(i,j)\in\Omega}\vartheta_t(i,j)\cdot\vartheta_x(i,j),\end{aligned}\)
\(\begin{aligned}S_5&=\sum_{(i,j)\in\Omega}\vartheta_t(i,j)\cdot\vartheta_y(i,j),\end{aligned}\)
全部是自相关和互相关参数,ϑx (i, j) 和 ϑy(i, j) 是水平和垂直梯度,ϑt(i, j) 是位置 (i, j) 处样本的时间梯度 j,计算公式为(10)-(12):
\(\vartheta_x(i,j)=\frac{\partial I_0(i,j)}{\partial x}+\frac{\partial I_1(i,j)}{\partial x}\)
\(\begin{aligned}\vartheta_y(i,j)&=\frac{\partial I_0(i,j)}{\partial y}+\frac{\partial I_1(i,j)}{\partial y}\end{aligned}\)
\(\vartheta_t(i,j)=I_0(i,j)-I_1(i,j).\)
导出 (vx , vy) 后,通过沿着运动轨迹对列表 0 和列表 1 预测样本进行插值来计算块当前位置 (i, j) 处的最终双向预测信号 Ic(i, j)(如图8所示)基于Hermite插值,即
\(\begin{aligned}I’c(i,j)&=\frac{1}{2}(I_0(i,j)+I_1(i,j)+\sigma_{\mathrm{BDOF}}),\end{aligned}\)
\(\begin{aligned}\sigma_{\mathrm{BDOF}}&=v_{x}(\frac{\partial I_{0}(i,j)}{\partial x}-\frac{\partial I_{1}(i,j)}{\partial x})\\&+v_{\mathrm{y}}(\frac{\partial I_{0}(i,j)}{\partial y}-\frac{\partial I_{1}(i,j)}{\partial y}).\end{aligned}\)
Subblock-based temporal motion vector prediction (SbTMVP)
VVC 支持基于子块的时间运动矢量预测(SbTMVP)方法。 与 HEVC 中的时间运动矢量预测 (TMVP) 类似,SbTMVP 使用并置图片(collocated picture)中的运动场来改进当前图片中 CU 的运动矢量预测和Merge模式。 SbTVMP和TMVP 使用相同的并置图片 。
SbTMVP 与 TMVP 的不同主要有以下两个方面:
– TMVP 在 CU 级别预测运动,但 SbTMVP 在子 CU 级别预测运动;
– TMVP 从并置图片中的并置块获取时间运动矢量(并置块是相对于当前 CU 的右下或中心块),而 SbTMVP 在从并置图片获取时间运动信息之前应用运动移位 ,其中运动位移是从当前 CU 的空间相邻块之一的运动矢量获得的。
SbTVMP 过程如图 34 所示。SbTMVP 分两步预测当前 CU 内子 CU 的运动矢量。 第一步,检查图 34 (a) 中的块A1。 如果A1具有使用并置图片作为其参考图片的运动矢量,则选择该运动矢量作为要应用的运动移位。 如果A1未在帧间预测模式下进行编码或 MV 未指向并置图片,则将运动偏移设置为 (0, 0)。

第二步,应用步骤 1 中识别的运动移位(即添加到当前块的坐标),以从并置图片中获取子 CU 级运动信息(运动矢量和参考索引),如图 34(b)所示。 图 34 (b) 中的示例假设运动移位设置为块 A1 的运动。 然后,对于每个子CU,使用并置图片中其对应块(覆盖中心样本的最小运动网格)的运动信息来导出子CU的运动信息。 在识别出并置子CU的运动信息之后,以与HEVC的TMVP过程类似的方式将其转换为当前子CU的参考索引和运动矢量,其中应用时间运动缩放以将时间运动矢量的参考图片与当前CU的参考图片对齐。
当前CU的中心位置的运动信息,是从并置图片中包含移位的中心位置的块的运动信息导出的,在图5中标记为MV3。如果包含移位的中心位置的块没有进行帧间编码,则认为SbTMVP候选不可用。在对应的子块没有被帧间编码的情况下,当前子块的MV被设置为中心位置的MV。

在VVC中,包含SbTVMP候选者和仿射Merge候选者的组合的基于子块的Merge列表被用于基于子块的Merge模式的信令。 SbTVMP 模式由序列参数集 (SPS) 标志启用/禁用。 如果启用 SbTMVP 模式,则将 SbTMVP 预测器添加为基于子块的Merge候选者列表的第一个条目,后面是仿射合并候选者。 基于子块的Merge列表的大小在SPS中用信号通知,并且基于子块的Merge列表的最大允许大小在VVC中是5。
SbTMVP 中使用的子 CU 大小固定为 8×8,与仿射合并模式一样,SbTMVP 模式仅适用于宽度和高度都大于或等于 8 的 CU。
附加SbTMVP Merge候选的编码逻辑与其他Merge候选相同,即对于P或B切片中的每个CU,执行附加RD检查来决定是否使用SbTMVP候选。
VVC中的collocated picture
collocated picture 是参考帧列表中先前已编码的帧。 在VVC中,每一帧的picture header中通过 ph_collocated_from_l0_flag 和 ph_collocated_ref_idx 两个参数来显示地指定使用哪一帧作为collocated picture。
ph_collocated_from_l0_flag 等于 1 指定用于TMVP collocated picture是从 RPL0 导出的。 ph_col located_from_l0_flag 等于 0 指定用于TMVP collocated picture是从 RPL1 导出的。 当 ph_temporal_mvp_enabled_flag 和 pps_rpl_info_in_ph_flag 都等于 1 并且 num_ref_entries[1][RplsIdx[1]] 等于 0,则推断 ph_col located_from_l0_flag 的值等于 1。
ph_collocated_ref_idx 指定用于TMVP collocated picture的参考索引。 当ph_collocated_from_l0_flag等于1时,ph_col located_ref_idx引用RPL0中的帧,并且ph_col located_ref_idx的值应在0到num_ref_entries[0][RplsIdx[0]]-1的范围内,包括0和num_ref_entries[0][RplsIdx[0]]-1。 当ph_collocated_from_l0_flag等于0时,ph_col located_ref_idx引用RPL1中的帧,并且ph_col located_ref_idx的值应在0到num_ref_entries[1][RplsIdx[1]]-1的范围内,包括0和num_ref_entries[1][RplsIdx[1]]-1。
在VTM中,首先会在Lo和L1中寻找可以使用的参考帧,如果L0和L1的参考帧都可用,则选择其中QP比较大的帧,如果某个列表不可用,则选择另外一个列表,如果都不可用,则关闭TMVP。
Adaptive motion vector resolution (AMVR)
在 HEVC 中,当slice header中的 use_integer_mv_flag 等于 0 时,运动矢量差(MVD)(CU 的运动矢量和预测运动矢量之间)以四分之一亮度样本为单位用信号表示。 在VVC中,引入了CU级自适应运动矢量分辨率(AMVR)方案。 AMVR允许CU的MVD以不同的精度进行编码。 根据当前CU的模式(正常AMVP模式或仿射AVMP模式),可以如下自适应地选择当前CU的MVD:
– 正常 AMVP 模式:四分之一亮度样本、半亮度样本、整数亮度样本或四亮度样本。
– 仿射 AMVP 模式:四分之一亮度样本、整数亮度样本或 1/16 亮度样本。
如果当前CU具有至少一个非零MVD分量,则有条件地用信号发送CU级MVD分辨率指示。 如果所有 MVD 分量(即,参考列表 L0 和参考列表 L1 的水平和垂直 MVD)均为零,则推断四分之一亮度样本 MVD 分辨率。
对于具有至少一个非零MVD分量的CU,用信号发送第一标志以指示是否将四分之一亮度样本MVD精度用于CU。 如果第一标志为0,则不需要进一步的信令并且四分之一亮度样本MVD精度用于当前CU。 否则,用信号发送第二标志以指示将半亮度样本或其他MVD精度(整数或四亮度样本)用于正常AMVP CU。 在半亮度样本的情况下,半亮度样本位置使用 6 抽头插值滤波器而不是默认的 8 抽头插值滤波器。 否则,用信号发送第三标志以指示对于正常AMVP CU使用整数亮度样本还是四亮度样本MVD精度。 在仿射 AMVP CU 的情况下,第二个标志用于指示是使用整数亮度样本还是 1/16 亮度样本 MVD 精度。 为了确保重建的 MV 具有预期的精度(四分之一亮度样本、半亮度样本、整数亮度样本或四亮度样本),CU 的运动矢量预测器将四舍五入为相同的精度。 与 MVD 相加之前的精度与 MVD 的精度相同。 运动矢量预测值向零舍入(即,负运动矢量预测值向正无穷大舍入,正运动矢量预测值向负无穷大舍入)。
编码器使用 RD 检查确定当前 CU 的运动矢量分辨率。 为了避免总是对每个 MVD 分辨率执行四次 CU 级 RD 检查,在 VTM 中,仅有条件地调用除四分之一亮度样本之外的 MVD 精度的 RD 检查。 对于普通 AVMP 模式,首先计算四分之一亮度样本 MVD 精度和整数亮度样本 MV 精度的 RD 成本。 然后,将整数亮度样本MVD精度的RD成本与四分之一亮度样本MVD精度的RD成本进行比较,以决定是否有必要进一步检查四亮度样本MVD精度的RD成本。 当四分之一亮度样本MVD精度的RD成本远小于整数亮度样本MVD精度的RD成本时,跳过四亮度样本MVD精度的RD检查。 然后,如果整数亮度样本 MVD 精度的 RD 成本显着大于先前测试的 MVD 精度的最佳 RD 成本,则跳过半亮度样本 MVD 精度的检查。 对于仿射 AMVP 模式,如果在检查仿射合并/跳过模式、合并/跳过模式、四分之一亮度样本 MVD 精度正常 AMVP 模式和四分之一亮度样本 MVD 精度仿射 AMVP 的速率失真成本后未选择仿射帧间模式,则不检查 1/16 亮度样本 MV 精度和 1-pel MV 精度仿射帧间模式。 此外,在四分之一亮度样本MV精度仿射帧间模式中获得的仿射参数被用作1/16亮度样本和四分之一亮度样本MV精度仿射帧间模式中的起始搜索点。
HEVC Picture Buffering Management
1 POC and DPB
HEVC 中的每个图片都分配有一个图片顺序计数 (picture order count, POC) 值,表示为 PicOrderCntVal。 它具有三个主要用途:唯一地标识图片,指示相对于同一 CVS 中其他图片的输出位置,以及在较低级别的 VCL 解码过程中执行运动矢量缩放。 同一CVS中的所有图片必须具有唯一的POC值。 来自不同CVS的图片可以共享相同的POC值,但是图片仍然可以被唯一地识别,因为不可能将来自一个CVS的图片与另一CVS的任何图片混合。 CVS 中允许 POC 值存在间隙,即,输出顺序连续的两个图片之间的 POC 值差异可以相差超过1(事实上,连续图片的 POC 值的差异量可以任意变化) 。
图片的 POC 值由slice header 中的 slice_pic_order_cnt_lsb 码字表示。 允许的 POC 值的范围是从 -231 到 231 – 1,因此为了节省 slice header 中的比特,仅用信号通知 POC 值的最低有效位 (POC LSB)。 用于 POC LSB 的位数可以在 4 到 16 之间,并在 SPS 中用信号通知。 由于在 slice header 中仅用信号通知 POC LSB,因此当前图片的最高有效 POC 值位 (POC MSB) 是从称为 prevTid0Pic 的先前图片导出的。 为了即使图片被移除,POC 推导也能以相同的方式工作,prevTid0Pic 被设置为时间层 0 的最近的先前图片,该图片不是 RASL 图片、RADL 图片或子层非参考图片。 解码器通过将当前图片的POC值与前一个图片的POC值进行比较来导出POC MSB值。
HEVC中的解码图片缓冲器(DPB)是包含解码图片的缓冲器。 除当前图片之外的解码图片可以存储在DPB中,因为它们需要参考,或者因为它们尚未输出,这是启用乱序输出所必需的。 请注意,当前解码的图片也存储在 DPB 中。 图 2.12 显示了两个示例引用结构,它们都需要至少三张图片的 DPB 大小。 图2.12a中的图片P1和P2都在P3之后输出,因此在P3解码时都需要将其存储在DPB中。 因此,DPB 需要能够同时存储 P1、P2 和 P3。 在图2.12b中,每个图片使用两个参考图片,因此DPB也需要足够大以同时存储三个图片。 图2.12b中的参考结构是所谓的低延迟B结构的示例,其中广泛使用双向预测而没有任何乱序输出。

解码器需要分配用于解码特定比特流的最小DPB大小由sps_max_dec_pic_buffering_minus1 码字来发信号通知,其可以针对序列参数集中的每个时间子层发送。 HEVC的第一版本中允许的最大可能的DPB大小是16,但是根据图片大小和所使用的解码能力的“级别”的组合,最大大小可以进一步受到限制。 请注意,HEVC 指定要包括在 DPB 中的当前图片,因此 DPB 大小为 1 将不允许任何参考图片。 如果DPB大小为1,则所有图片都必须进行帧内编码。
DPB中的图片被标记以指示它们的参考状态。 DPB中的每张图片都被标记为“不用于参考”、“用于短期参考”或“用于长期参考”。 通常将这些类型的图片分别称为非参考图片、短期图片和长期图片。
参考图片要么是短期图片,要么是长期图片。不同之处在于,长期图片可以在DPB中保存的时间比短期图片长得多。有一条规则决定了短期图片可以在DPB中停留多长时间。由当前图片、prevTid0Pic、DPB中的短期参考图片和DPB内等待输出的图片组成的图片集的POC跨度必须在POC LSB覆盖的POC范围的一半以内。该规则保证了POC MSB推导的正确性,并通过使解码器能够识别丢失的短期图片来提高误差鲁棒性。
非参考图片是不用作参考但如果以后需要输出时仍可以保留在DPB中的图片。
如图 2.13 所示,每个解码图像的图像标记都会发生变化。 图片被解码后,最初总是被标记为短期图片。 短期图片可以保持短期图片或改变为非参考图片或长期图片。 长期图片可能会保持长期图片或变成非参考图片,但它们永远不能再变成短期图片。 非参考图片永远不能再次成为参考图片。

DPB中的图片可以被保存以供将来输出,无论它是参考图片还是非参考图片。 当图片已被解码时,它通常等待输出,除非 slice header 中的pic_output_flag等于0或者图片是与CVS中的第一图片相关联的RASL图片。 如果是这种情况,则不会输出图片。
图片标记和图片输出是在单独的过程中完成的,但是当图片既是非参考图片并且不等待输出时,DPB中的图片存储缓冲器被清空并且可以用于存储将来的解码图片。 编码器负责管理图片标记和图片输出,以便 DPB 中的图片数量不超过 sps_max_dec_pic_buffering_minus1 指示的 DPB 大小。
SPS中与图片输出相关的另外两个码字是
sps_max_num_reorder_pics 和 sps_max_latency_increase_plus1,两者都可以针对每个时间子层发送。 sps_max_num_reorder_pics,此处表示为NumReorderPics,指示在解码顺序中可以在任何图片之前并且在输出顺序中在其之后的图片的最大数量。 图 2.12a 中的参考结构的 NumReorderPics 值为 2,因为图片 P3 有两个图片在解码顺序上位于其前面,但在输出顺序上位于其后面。 图 2.12b 的 NumReorderPics 为零,因为没有图片乱序发送。
sps_max_latency_increase_plus1 用于指示 MaxLatencyPictures,它指示在输出顺序中可以在任何图片之前并且在解码顺序中在该图片之后的图片的最大数量。 图 2.14 显示了 NumReorderPics 和 MaxLatencyPictures 之间的区别。 NumReorderPics 在此等于 1,因为 P1 是唯一乱序发送的图片。 MaxLatencyPictures 设置为 4,因为图片 P2、P3、P4 和 P5 在输出顺序上都先于 P1。 此参考结构的最小 DPB 大小为 3。

可以说NumReorderPics表示DPB中处理乱序图片所需的图片存储的最小数量,而MaxLatencyPictures表示由乱序图片引起的以图片为单位的最小编码延迟量。
对于低延迟应用,建议使用不会因乱序输出而导致编码延迟的参考结构。 这是通过确保解码顺序和输出顺序相同来实现的,这可以通过发信号通知 NumReorderPics 或 MaxLatencyPictures 或两者都等于 0 来表示。
2 Reference Picture Sets
将图片标记为“用于短期参考”、“用于长期参考”或“不用于参考”的过程是使用参考图片集(RPS)概念来完成的。 RPS是在每个slice header中用信号通知的一组图片指示符,并且由一组短期图片和一组长期图片组成。 在图片的第一个片头被解码之后,DPB中的图片被标记为由RPS指定的。
RPS的短期图片部分中指示的DPB中的图片被保留为短期图片。 将RPS中的长期图像部分中指示的DPB中的短期或长期图像转换为或保留为长期图像。 最后,DPB中RPS中没有指示符的图片被标记为未使用以供参考。 因此,可以用作对按照解码顺序的任何后续图片进行预测的参考的所有已经解码的图片必须被包括在RPS中。
RPS 由一组图片顺序计数 (POC) 值组成,用于识别 DPB 中的图片。 除了用信号发送 POC 信息之外,RPS 还为每张图片发送一个标志。 每个标志指示对应的图片是否可供当前图片参考。 注意,即使参考图片被信号通知为对于当前图片不可用,它仍然被保存在DPB中并且可以供稍后参考并用于解码未来的图片。 根据 POC 信息和可用性标志,可以创建如表 2.3 所示的五个参考图片列表。

列表RefPicSetStCurrBefore由可用于当前图片的参考并且具有低于当前图片的POC值的POC值的短期图片组成。 RefPicSetStCurrAfter 由可用的短期图片组成,其 POC 值高于当前图片的 POC 值。 RefPicSetStFoll是包含对于当前图片不可用但可以用作用于按解码顺序解码后续图片的参考图片的所有短期图片的列表。 最后,列表RefPicSetLtCurr和RefPicSetLtFoll分别包含可用于和不可用于当前图片的参考的长期图片。
图 2.15 和表 2.4 显示了使用三个时间子层的示例引用结构以及按解码顺序排列的每个图片的 RPS 列表的内容。
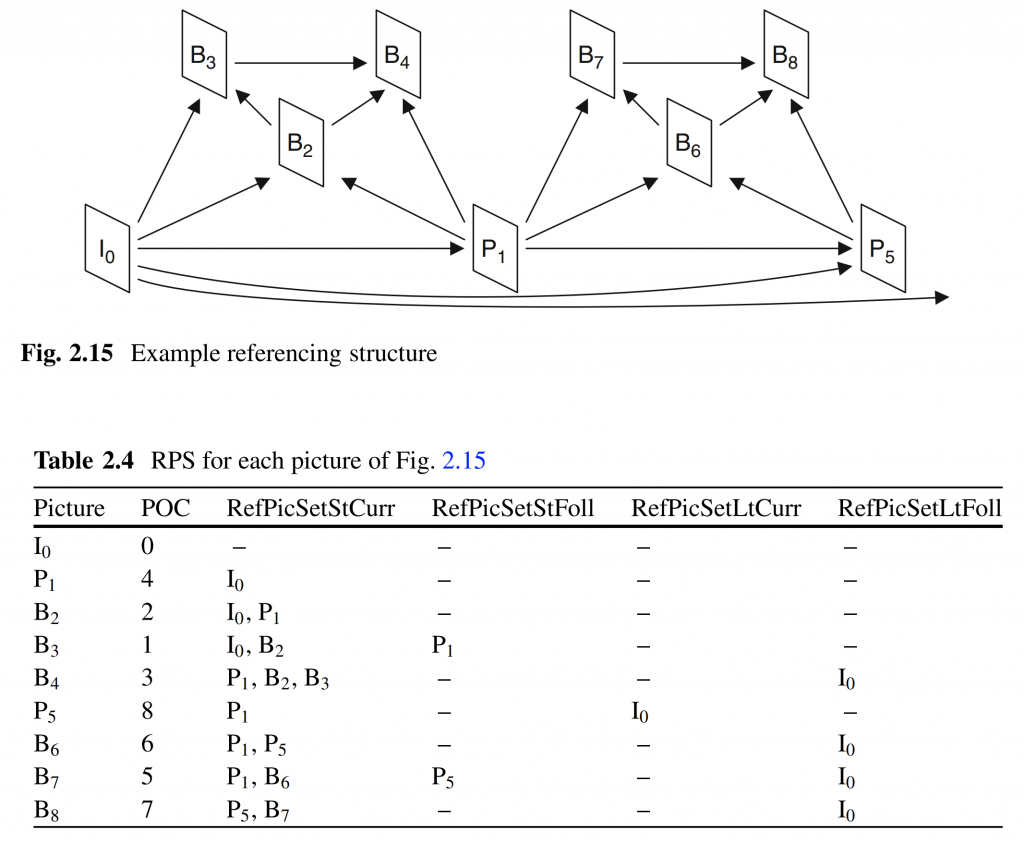
IDR图片重置编解码器,包括将DPB中的所有图片转变为非参考图片。 由于IDR图片的RPS是空的,因此没有为IDR图片用信号发送RPS语法。 因此表 2.4 中的所有列表对于 IDR 图片 I0 都是空的。 在图片B3处,图片P1被放入RefPicSetStFoll中,因为P1未被B3引用。 然而,P1 保留在 DPB 中,因为它用于将来的图片。 在图片B4处,本例中I0被制作为长期图片,因此由于B4没有引用它,因此将其放入RefPicSetLtFoll中。 在图片P5处,编码器通过根本不将图片B2和B3包括在RPS中来使图片B2和B3成为非参考图片。 同时,图片 I0 被移动到 RefPicSetLtCurr,因为它被 P5 引用。 此后,I0 保存在 RefPicSetLtFoll 中以供以后使用。
编码器需要确保RefPicSetStCurr和RefPicSettRoll中指示的每个图片都存在于DPB中。如果不是这种情况,解码器应该将其推断为比特流错误,并采取适当的行动。然而,如果在RPS中的条目的DPB中不存在被指示不用于当前图片的参考的对应图片,则解码器不采取任何动作,因为这种情况可能由于移除个别子层非参考图片或整个较高时间子层而发生。
尽管没有针对IDR图片发送RPS,但是CRA和BLA图片都可以在其RPS中具有图片,使得相关联的RASL图片可以使用RPS中的那些图片作为预测的参考。但是,对于CRA和BLA图片,要求RefPicSettCurr和RefPicSetLtCurr列表均为空。
3 Reference Picture Set Signaling
对于RPS中的每个图片,用信号发送三条信息:POC信息、可用性状态以及图片是短期图片还是长期图片。
短期图片的 POC 信息以两组方式发送。 组 S0 首先被发信号通知,它由 POC 值低于当前图片的所有短期图片组成。 该组之后是组 S1,其包含具有比当前图片更高的 POC 值的所有短期图片。 每组的信息按照相对于当前图片的POC距离顺序发送,从最接近当前图片的POC值的POC值开始。 对于每张图片,都会发出相对于前一张图片的 POC 增量信号。 当前图片充当每组中第一张图片的前一张图片,因为第一张图片没有前一张图片。
通过 POC 增量对长期图片进行编码可能会导致非常长的码字,因为长期图片可以在 DPB 中保留很长时间。 因此,长期图像而是通过其 POC LSB 值来表示。 用于slice header POC LSB 值的相同位数也用于长期图片。 解码器会将 RPS 中发信号通知的每个 POC LSB 值与 DPB 中图片的 POC LSB 值进行匹配。 由于 DPB 中可能有多个具有相同 POC LSB 值的图片,因此还可以选择发送长期图片的 POC MSB 信息。 当存在解码器无法正确识别图片的风险时,必须发送此 MSB 信息。 避免这种风险的一种方法是,当相应的 POC LSB 值已被两个或多个不同的长期图片使用时,始终用信号发送长期图片的 POC MSB 信息。
RPS 中每个图片的可用性状态由一位标志表示,其中“1”表示该图片可供当前图片参考,“0”表示不可用。
表 2.5 显示了图 2.15 中图片 B7 的示例 RPS 语法。 表中的第一列显示语法是否与发信号通知短期图片或长期图片相关。 第二列包含每个语法元素的 HEVC 规范名称。 第三列表示RPS中的相关图片,第四列表示示例中语法元素的值。 第五列显示语法元素的类型,其中“uvlc”表示通用可变长度代码,“flag”是一位二进制标志,“flc”是固定长度代码。 最后一列显示使用类型对每个语法元素的值进行编码的结果位。

图2.15中图片B7的POC值为5,其RPS包含3个短期图片; S0组中的图片P1和S1组中的图片B6和P5。 RPS 的前两个语法元素传达 S0 和 S1 中的图片数量; 这是由 uvlc 代码“010”和“011”编码的。 然后用信号发送组S0中的图像。 P1 的 POC 增量为 1,因为它的 POC 值为 4,并且当前图片的 POC 值等于 5。在编码之前,POC 增量减去 1,因此最终信号值为 0,这导致 uvlc 代码“1” 。 当前图片B7以图片P1为参考; 这是由标志“1”表示的。
接下来的语法元素涵盖了 S1 中的图片。 当前图片的 POC 值等于 5,因此代码字“1”用于 B6,因为其 POC 值等于 6。图片 B6 也用于由标志“1”指示的当前图片的参考。 S1 中的第二张图片是 P5,其 POC 值为 8。它是相对于 S1 中的前一张图片(B6,POC 值为 6)进行编码的。增量为 2,减 1 等于 1,编码为 ‘010’。 当前图片B7不参考图片P5; 这是由标志“0”表示的。
RPS 中的下一个码字表示 RPS 中长期图像的数量,它是 1,并且使用“010”进行 uvlc 编码。 然后用信号通知长期图像I0的POC LSB值。 这是通过代码字“00000000”假设 8 位用于发送 POC LSB 值。 长期图片I0不被当前图片B7参考; 这是用标志‘0’来表示的。 最后,由于 DPB 中没有其他图片共享相同的 POC LSB 值,因此不会针对该长期图片发送 POC MSB 信息; 这是用当前标志“0”来表示的。
出于弹性原因,RPS信息在每个 slice header 中用信号发送,但是对于每个 slice 按原样重复RPS信息可能会花费许多比特。不仅可以将图片分割成必须重复RPS的多个slice,比特流中的图片通常通过重复相同的GOP结构来编码,因此对于在GOP结构中共享相同位置的图片重复相同的RPS信息。
为了利用冗余并降低总体比特成本,可以在 SPS 中发送一些 RPS 语法在 slice header 中引用。 RPS的短期图像部分是相对于当前图像的POC值进行编码的。 这使得可以将多个短期RPS部分存储在SPS中的列表中,并且仅在 slice header 中用信号发送列表索引。 该列表可以包含用于GOP结构中的每个画面位置的一个RPS。 然后,SPS 中的 RPS 数量将等于 GOP 长度,并且每个片将仅需要发送列表索引以便用信号通知其短期图像部分。
发送每个GOP位置的RPS信息可能需要SPS中相对较多的比特,比如对于一些GOP结构存在数百比特。 为了节省 SPS 中的比特,HEVC 中可以选择使用 RPS 预测。 这要求以 GOP 解码顺序发送 RPS,并利用每个 RPS 与前一个类似的事实。 可以按照解码顺序将图片参考从一个RPS移除到下一个RPS,但是相对于前一RPS最多只能添加一张新图片。 HEVC 中的 RPS 预测机制正在利用此属性,相对于显式信令,可以实现 SPS 中 RPS 比特数最多减少 50%。
4 Reference Picture Lists
当P或B slice的 slice header 已被解码时,解码器为当前slice设置参考图片列表。 有两个参考图片列表,L0和L1。 L0 用于 P 和 B slice,而 L1 仅用于 B slice。 图2.16示出了使用五个参考图片进行预测的图片B7的参考图片列表示例。

首先,构建 L0 和 L1 的临时列表。 临时列表L0以RPS列表RefPicSetStCurrBefore中的图片开始,按POC值降序排序。 这些都是可供当前图片参考并且具有小于当前图片的POC值的POC值的短期图片。 因此图2.16中图片B7的临时列表L0以P1开始,随后是B2。 接下来是按 POC 值升序排序的 RPS 列表 RefPicSetStCurrAfter 中的图片,即图 2.16 中的 B6 和 P5。 最后添加可用的长期图片,因此图片I0是最后添加的图片。 图片B7的最终临时列表L0则为{P1、B2、B6、P5、I0}。 临时列表L1的设置与L0类似,但是RefPicSetStCurrBefore和RefPicSetStCurrAfter的顺序交换。 因此,图片B7的临时列表L1变为{B6、P5、P1、B2、I0}。
临时列表用于构建最终的L0和L1列表。L0和L1的长度在PPS中用信号发送,但可以被slice header 中的可选码字覆盖。列表的最大长度为15。如果L0或L1的指定长度分别小于临时列表L0或L2的长度,则通过截断相应的临时列表来构建最终列表。如果指定的长度大于相应临时列表的长度,则从临时列表中重复图片。例如,如果长度为2,L0等于{P1、B2},如果长度是9,则等于{P1,B2、B6、P5、I0、P1、B2、B6、P5}。启用比临时列表长的列表的原因是加权预测,以使不同的加权因子能够应用于相同的参考图片。
从临时列表构建 L0 和 L1 的另一种方法是通过显式列表信令。 在这种情况下,列表中的每个条目都有一个代码字,用于指定要使用临时列表中的哪个图片。 因此,如果指定L0的长度等于3,则有3个码字用于指定L0。 例如,如果这三个码字等于1、1、0,则当P1是临时列表L0中的第一图片且B2是第二图片时,列表L0变为{B2、B2、P1}。
最终列表L0和L1用于运动补偿。 对于单预测,为块指示一个运动向量和一个参考图片索引。 例如,如果块的信号索引等于 0,则 L0 中的第一张图片是用于运动补偿的图片。
POSIX 线程同步——条件变量
POSIX多线程程序设计. 作者 美 David R.Buten
条件变量是用来通知共享数据状态信息的。可以使用条件变量来通知队列已空、或队列非空、或任何其他需要由线程处理的共享数据状态。
当一个线程互斥地访问共享状态时,它可能发现在其他线程改变状态之前它什么也做不了。状态可能是对的和一致的,即没有破坏不变量,但但是线程就是对当前状态不感兴趣。例如,一个处理队列的线程发现队列为空时,它只能等待,直到有一个节点被填加进队列中。
例如,共享数据由一个互斥量保护。线程必须锁住互斥量来判定队列的当前状态,如判断队列是否为空。线程在等待之前必须释放锁(否则)其他线程就不可能插入数据),然后等待队列状态的变化。例如,线程可以通过某种方式阻塞自己,以便插入线程能够找到它的ID并唤醒它。但是这里有一个问题,即线程是运行于解锁和阻塞之间。
如果线程仍在运行,而其他线程此时向队列中插入了一个新的元素,则其他线程无法确定是否有线程在等待新元素。等待线程已经查找了队列并发现队列为空,解锁互斥量,然后阻塞自己,所以无法知道队列不再为空。更糟糕的是,它可能没有说明它在等待队列非空,所以其他线程无法找到它的线程ID,它只有永远等下去了。解锁和等待操作必须是原子性的,以防止其他线程在该线程解锁之后、阻塞之前锁住互斥量,这样其他线程才能够唤醒它。
等待条件变量总是返回锁住的互斥量。
这就是为什么要使用条件变量的原因。条件变量是与互斥量相关、也与互斥量保护的共享数据相关的信号机制。在一个条件变量上等待会导致以下原子操作:释放相关互斥量,等待其他线程发给该条件变量的信号(唤醒一个等待者)或广播该条件变量(唤醒所有等待者)。当等待条件变量时,互斥量必须治终锁住:当线程从条件变量等待中醒来时,它重新继续锁住互斥量。
条件变量不提供互斥。需要一个互斥量来同步对共享数据(包括活等待的谓词)的访问,这就是为什么在等待条件变量时必须指定一个互斥量。通过将解锁操作与等待条件变量原子化,Pthreads系统确保了在释放互斥量和等待条件变量之间没有线程可以改变与条件变量相关的“谓词”(如队列满或者队列空)。
为什么不将互斥量作为条件变量的一部分来创建呢?首先,互斥量不仅与条件变量一起使用,而且还要单独使用;其次,通常一个互斥量可以与多个条件变量相关。例如,队列可以为空,也可以为满。虽然可以设置两个条件变量让线程等待不同的条件,但只能有一个互斥量来协调对队列头的访问。
一个条件变量应该与一个谓词相关。如果试图将一个条件变量与多个谓词相关,或者将多个条件变量与一个谓词相关,就有陷入死锁或者竞争问题的危险。只要小心使用,可能不会有什么问题,但是很容易搞混你的程序,并且通常也不值得冒险。原则是:第一,当你在多个谓词之间共享一个条件变量时,必须总是使用广播,而不是发信号;第二,信号要比广播有效。
条件变量和谓词都是程序中的共享数据。它们被多个线程使用,可能是同时使用。由于你认为条件变量和谓词总是一起被锁定的,所以容易让人记住它们总是被相同的互斥量控制。在没有锁住互斥量前就发信号或广播条件变量是可能的(合法的,通常也是合理的),但是更安全的方式是先锁住互斥量。
下图显示了三个线程与一个条件变量交互的时间图。圆形框代表条件变量,三条线段代表三个线程的活动。

当线段进入圆形框时,既表明线程使用条件变量做了一些事。当线程对应的线段在到达圆形框中线之前停止,表明线程在等待条件变量;当线程线段到达中线之下时,表明它在发信号或广播来唤醒等待线程。
线程1等条件变量发信号,由于此时没有等待线程,所以没有任何效果。线程1然后在条件变量上等待。线程2同样在条件变量上阻塞,随后线程3发信号唤醒在条件变量上等待的线程1。线程3然后在条件变量上等待。线程1广播条件变量,唤醒线程2和线程3。随后,线程3在条件变量上等待。一段时间后,线程3的等待时间超时,线程3被唤醒。
1 创建和释放条件变量
pthread_cond_t cod = PTHREAD_COND_INITIALIZER
int pthread_cond_init (pthread_cond_t *cond,
pthread_condattr_t *condattr);
int Pthread_cond_destroy (pthread_cond_t *ccond)
程序中由pthread_cond_t类型的变量来表示条件变量。永远不要拷贝条件变量,因为使用条件变量的备份是不可知的,这就像是打一个断线的电话号码并等待回答一样。例如,一个线程可能在等待条件变量的一个拷贝,同时其他线程可能广播或发信号给该条件变量的其他拷贝,则该等待线程就不能被唤醒。不过,可以传递条件变量的指针以使不同函数和线程可以使用它来同步。
大部分时间你可能在整个文件范围内(即不在任何函数内部)声明全局或静态类型条件变量。如果有其他文件需要使用,则使用全局(extern)类型;否则,使用静态(static)类型。如下面实例cond_static.c所示,如果声明了一个使用默认属性值的静态条件变量,则需要使用PTHREAD_COND_INITIALIZER宏初始化。
#include <pthread.h>
#include "errors.h"
/*
* Declare a structure, with a mutex and conddition variable
* statically initialized. This is the same asusing
* pthread_mutex_init and pthread_cond_init, with the ddefault
* attributes.
*/
typedef struct_my_struct_tag {
pthread_mutex_t mutex; /* Protects access to value */
pthread_cond_t cond; /* Signals change to value */
int value; /* Access protected by mutex */
} my_struct_t;
my_struct_t data = {
PTHREAD_MUTEX_INITIALIZER, PTHREAD_COND_INITIALIZER0};
int main (int argc, char *argv[]){
return 0;
}当声明条件变量时,要记住条件变量与相关的谓词是”链接”在一起的。建议你将一组不变量、谓词和它们的互斥量,以及一个或多个条件变量封装为一个数据结构的元素,并仔细地记录下它们之间的关系。
有时无法静态地初始化一个条件变量,例如,当使用malloc分配一个包含条件变量的结构时。这时,你需要调用pthread_cond_init来动态他初始化条件变量,如以下实例cond_dynamic.c所示。还可以动态初始化静态声明的条件变量,但是必须确保每个条件变量在使用之前初始化且仅初始化次。你可以在建立任何线程前初始化它,或者使用pthread_once。如果需要使用非默认属性初始化条件变量,必须使用动态初始化。
#include <pthread.h>
#include "errors.h"
/*
* Define a structure, with a mutex and condittion variable.
*/
typedef struct_my_struct_tag {
pthread_mutex_t mutex; /* Protects access to value */
pthread_cond_t cond; /* Signals change to value */
int value; /* Access protected by mutex */
} my_struct_t;
int main (int argc, char *argv[]) {
my_struct_t *data;
int status;
data = malloc (sizeof (my_struct_t));
if (data == NULL)
errno_abort ("Allocate structure");
status = pthread_mutex_init (&data->mutex, NULL);
if (status != 0)
err_abort (status, "Init mutex");
status = pthread_cond_init (&data->cond, NULL);
if (status != 0)
err_abort (status, "Init condition");
status = pthread_cond_destroy (&data->cond);
if (status != 0)
err_abort (status, "Destroy condition");
status = pthread_mutex_destroy (&data->mutex);
if (status != 0)
err_abort (status, "Destroy mutex");
(void)free (data);
return status;
}当动态初始化条件变量时,应该在不需要它时调用pthread_coind_destroy来释放它。不必释放一个通过PTHREAD_COND_INITIALIZER宏静不态初始化的条件变量。
当你确信没有其他线程在某条件变量上等待,或者将要等待、发信号或广播时,可以安全地释放该条件变量。判定上述情况的最好方式是在刚刚成功地广播了该条件变量、唤醒了所有等待线程的线程内,且确信不再有线程随后后使用它时安全释放。
2 等待条件变量
int pthread_cond_wait (pthread_cond_t *coned,
pthread_mutex_t *mutex);
int pthread_cond_timedwait (pthread_cond t *cond,
pthread_mutex_t *mutex, struct timespec *expiration);每个条件变量必须与一个特定的互斥量、一个谓词条件相关联。当线程等待条件变量时,它必须将相关互斥量锁住。记住,在阻塞线程之前,条件变量等待操作将解锁互斥量;而在重新返回线程之前,会再次锁住互斥量。
所有并发地(同时)等待同一个条件变量的线程必须指定同一个相关互斥量。例如,Pthreads不允许线程1使用互斥量A等待条件变量A,而线程2使用互斥量B等待条件变量A。不过,以下情况是十分合理的:线程1使用互斥量A等待条件变量A,而线程2使用互斥量A等待条件变量B。即有任何条件变量在特定时刻只能与一个互斥量相关联,而互斥量则可以同时与多个条件变量关联。
在锁住相关的互斥量之后和在等待条件变量之前,测试谓词是很重要的。如果线程发信号或广播一个条件变量,而没有线程在等待该条件变量时,则什么也没发生。如果在这之后,有线程调用pthread_cond_wait,则它将一直等待下去而无视该条件变量刚刚被广播的事实,这将意味着该线程可能永远不被唤醒。因为在线程等待条件变量之前,互斥量一直被锁住,所以,在测试谓词和等待条件变量之间无法设置谓词——互斥量被锁住,没有其他线程可以修改共享数据,包括谓词。
当线程醒来时,再次测试谓词同样重要。应该总是在循环中等待条件变量,来避免程序错误、多处理器竞争和假唤醒。以下实例cond.c,显示了如何等待条件变量。
wait_thread 线程睡眠一段时间以允许主线程在被唤醒之前条件变量等待操作,设置共享的谓词(data.value),然后发信号给条件变量。 wait_thread线程等待的时间由hibernation变量控制,默认是1秒。
如果程序带参数运行,则将该参数解析为整数值,保存在hibernation变量中。这将控制wait_thread线程在发送条件变量的信号前等待的时间。
主线程调用pthread_cond_timedwait函数等待至多2秒(从当前时间开始)。如果hibernation变量设置为大于两秒的值,则条件变量等待操作将超时,返回ETIMEDOUT。如果hibernation变量设为2秒,则主线程和wait_thread线程发生竞争,并且每次运行的结果可能不同。如果hibernation变量设置为小于2秒,则条件变量等待操作不会超时。
#include <pthread.h>
#include "errors.h"
typedef struct_my_struct_tag {
pthread_mutex_t mutex; /* Protects access to value */
pthread_cond_t cond; /* Signals change to value */
int value; /* Access protected by mutex */
} my_struct_t;
my_struct_t data = {
PTHREAD_MUTEX_INITIALIZER, PTHREAD_COND_INITIALIZER0};
int hibernation = 1; /* Default to 1 second */
/*
* Thread start routine. It will set the mainthread's predicate
* and signal the condition variable.
*/
void * wait_thread (void *arg) {
int status;
sleep (hibernation);
status = pthread_mutex_lock (&data.mutex);
if (status != 0)
err_abort (status, "Lock mutex");
data.value = 1; /* Set predicate */
status = pthread_cond_signal (&data.cond);
if (status != 0)
err_abort (status, "Signal condition");
status = pthread_mutex_unlock (&data.mutex);
if (status != 0)
err_abort (status, "Unlock mutex");
return NULL;
}
int main (int argc, char *argv[]) {
int status;
pthread_t wait_thread_id;
struct timespec timeout;
/*
* If an argument is specified, interpret it asthe number
* of seconds for wait thread to sleep before signaling the
* condition variable. You can play with this to see the
* condition wait below time out or wake normally.
*/
if (argc > 1)
hibernation = atoi (argv[1]);
/*
* Create wait_thread.
*/
status = pthread_create (
&wait_thread_id, NULL, wait_thread, NULL);
if (status != 0)
err_abort (status, "Create wait thread");
/*
* Wait on the condition variable for 2 seconnds, or until
* signaled by the wait_thread. Normally, wait_tthread
* should signal. If you raise "hibernation" above 2
* seconds, it will time out.
*/
timeout.tv sec = time (NULL) + 2;
timeout.tv nsec = 0;
status = pthread_mutex_lock (&data.mutex);
if (status != 0)
err_abort (status, "Lock mutex");
while (data.value == 0) {
status = pthread_cond_timedwait (
&data.cond, &data.mutex, &timeout);
if (status == ETIMEDOUT) {
printf ("Condition wait timed out.\n");
break;
}
else if (status != 0)
err_abort (status, "Wait on condition");
}
if (data.value 1= 0)
printf ("Condition was signaled.\n");
status = pthread_mutex_unlock (&data.mutex)1
if (status != 0)
err_abort (status, "Unlock mutex");
return 0;
}pthread_cond_wait函数是POSIX线程库中用于等待条件变量的函数之一。它的原理涉及到线程同步和互斥锁的概念。
在调用pthread_cond_wait之前,通常需要先获取一个互斥锁(pthread_mutex_lock),以确保在等待条件变量期间的线程安全性。然后,线程会检查一个条件,如果条件不满足,线程就会阻塞在pthread_cond_wait调用处,等待其他线程发出条件变量的信号。
当其他线程调用pthread_cond_signal或pthread_cond_broadcast函数时,条件变量会被发出信号。这些函数用于通知等待在条件变量上的线程,条件已经满足,或者在广播情况下,通知所有等待线程。此时,被阻塞的线程会被唤醒,并开始重新尝试获取互斥锁。
pthread_cond_wait的原理可以简述如下:
- 线程调用pthread_mutex_lock获取互斥锁,确保线程安全。
- 线程检查条件是否满足。如果条件满足,线程不会调用pthread_cond_wait,而是继续执行后续操作。
- 如果条件不满足,线程调用pthread_cond_wait,释放互斥锁并进入阻塞状态,等待条件变量的信号。
- 其他线程调用pthread_cond_signal或pthread_cond_broadcast发出条件变量的信号。
- 被阻塞的线程被唤醒,重新尝试获取互斥锁。
- 线程成功获取互斥锁后,继续执行后续操作。
需要注意的是,pthread_cond_wait函数的阻塞和唤醒是由操作系统内核实现的,因此具体的实现细节可能因操作系统而异。但是,POSIX线程库提供了一种标准接口,确保了跨平台的可移植性。